1. What is Scrapy CrawlSpider?
CrawlSpider is a derived class of Scrapy, and the design principle of the Spider class is to crawl only the web pages in the start_url list. In contrast, the CrawlSpider class defines some rules to provide a convenient mechanism for following links – extracting links from scraping Amazon web pages and continuing the crawl.
CrawlSpider can match URLs that meet certain conditions, assemble them into Request objects, and automatically send them to the engine while specifying a callback function. In other words, the CrawlSpider crawler can automatically retrieve connections according to predefined rules.
2. Creating a CrawlSpider Crawler for Scraping Amazon
scrapy genspider -t crawl spider_name domain_nameCreate Scraping Amazon crawler command:
For example, to create an Amazon crawler named “amazonTop”:
scrapy genspider -t crawl amzonTop amazon.comThe following words are the whole code:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider):
name = 'amzonTop '
allowed_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item
Rules is a tuple or list containing Rule objects. A Rule consists of parameters such as LinkExtractor, callback, and follow.
A. LinkExtractor: A link extractor that matches URL addresses using regex, XPath, or CSS.
B. callback: A callback function for the URL addresses extracted, optional.
C. follow: Indicates whether the responses corresponding to the extracted URL addresses will continue to be processed by the rules. True means they will, and False means they won’t.
3. Scraping Amazon Product Data
3.1 Create an Scraping Amazon crawler
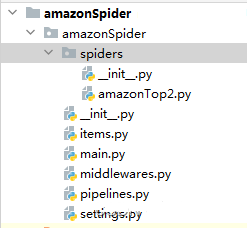
scrapy genspider -t crawl amazonTop2 amazon.comThe structure of Spider Code:
3.2 Extract the URLs for paging the product list and product details.
A. Extract all product Asin and rank from the product list page, i.e., retrieve Asin and rank from the blue boxes in the image.
B. Extract Asin for all colors and specifications from the product details page, i.e., retrieve Asin from the green boxes, which include Asin from the blue boxes.
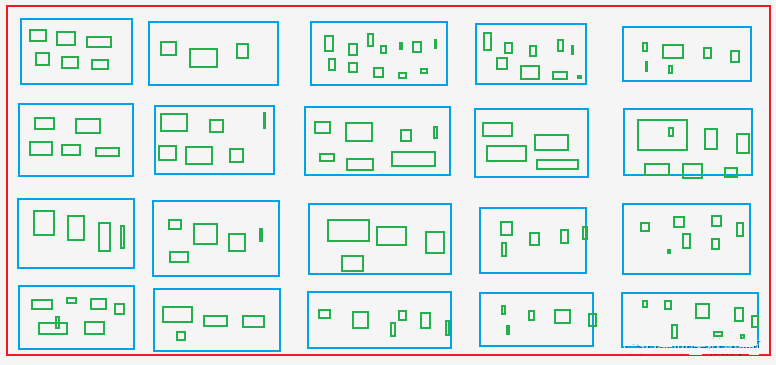
The Green Boxes: Like the Size X, M, L, XL, and XXL for clothes in shopping sites.
Spider file: amzonTop2.py
import datetime
import re
import time
from copy import deepcopy
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
rules = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}
if "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f"https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param response:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?),"refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r',"parentAsin":"(.*?)",', str(response.text))[-1]
except:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
except:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f"https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
for pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Ships from"]/div//span//text()').extract()
# 物流方
try:
delivery = ships_from_list[-1]
except:
delivery = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
if seller == "":
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# else:
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
except:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
except:
price = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
if brand == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
if pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
# material
try:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
# shape
shape = pro_detail['Shape'] if "Shape" in key_v else ""
if shape == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
# style
# five_points
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num =
# style
# manufacturer
try:
Manufacturer = pro_detail['Manufacturer'] if "Manufacturer" in str(pro_detail) else " "
except:
Manufacturer = ""
item_weight = pro_detail['Item Weight'] if "Weight" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# product_material
try:
product_material = pro_detail['Material']
except:
product_material = ''
# fabric_type
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list:
try:
star_1 = star_list[0].strip()
except:
star_1 = 0
try:
star_2 = star_list[1].strip()
except:
star_2 = 0
try:
star_3 = star_list[2].strip()
except:
star_3 = 0
try:
star_4 = star_list[3].strip()
except:
star_4 = 0
try:
star_5 = star_list[4].strip()
except:
star_5 = 0
else:
star_1 = 0
star_2 = 0
star_3 = 0
star_4 = 0
star_5 = 0
if "Date First Available" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
else:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# reviews_num, ratings_num
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=seller
item['seller_link']= seller_link
item['brand_link']= brand_link
item['pic_link'] =pic_link
item['title']=title
item['brand']=brand
item['star']=star
item['price']=price
item['color']=color
item['pattern']=pattern
item['material']=material
item['shape']=shape
item['five_points']=five_points
item['size_num']=size_num
item['color_num']=color_num
item['Manufacturer']=Manufacturer
item['item_weight']=item_weight
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=fabric_type
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
yield item
When collecting a substantial amount of data, change the IP and handle captcha recognition.
4. Methods for Downloader Middlewares
4.1 process_request(self, request, spider)
A. Called when each request passes through the download middleware.
B. Return None: If no value is returned (or return None explicitly), the request object is passed to the downloader or to other process_request methods with lower weight.
C. Return Response object: No further requests are made, and the response is returned to the engine.
D. Return Request object: The request object is passed to the scheduler through the engine. Other process_request methods with lower weight are skipped.
4.2 process_response(self, request, response, spider)
A. Called when the downloader completes the HTTP request and passes the response to the engine.
B. Return Response: Passed to the spider for processing or to other download middleware’s process_response method with lower weight.
C. Return Request object: Passed to the scheduler through the engine for further requests. Other process_request methods with lower weight are skipped.
D. Configure middleware activation and set weight values in settings.py. Lower weights are prioritized.
middlewares.py
4.3 Set up proxy IP
class ProxyMiddleware(object):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True
return request
class AmazonspiderDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'the cookie pasted from browser'
# cookies_str transfer to cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
4.5 Get Scraping Amazon’s verification code for unblocking from Amazon.
def captcha_verfiy(img_name):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if result:
result = result.replace(' ', '')
return result
def download_captcha(captcha_url):
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Download done!")
except Exception as e:
print("Download log error!")
class AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f"https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, we just need to make sure you're not a robot" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, we just need to make sure you're not a robot" not in str(response2.text):
return response2
else:
return request
else:
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
That is all code about Scraping Amazon data.
If any help please let OkeyProxy Support know.
Recommended Proxy Suppliers: Okeyproxy – Top 5 Socks5 Proxy Provider with 150M+ Residential Proxies from 200+ Countries. Get 1GB free Trial of Residential Proxies Now!

