1. ¿Qué es Scrapy CrawlSpider?
CrawlSpider es una clase derivada de Scrapy, y el principio de diseño de la clase Spider es rastrear sólo las páginas web de la lista start_url. Por el contrario, la clase CrawlSpider define algunas reglas para proporcionar un mecanismo conveniente para el seguimiento de enlaces - extracción de enlaces de raspado Amazon páginas web y continuar el rastreo.
CrawlSpider puede emparejar URLs que cumplan ciertas condiciones, ensamblarlas en objetos Request, y enviarlas automáticamente al motor mientras se especifica una función callback. En otras palabras, el rastreador CrawlSpider puede recuperar automáticamente conexiones de acuerdo con reglas predefinidas.
2. Creación de una araña CrawlSpider para el scraping de Amazon
scrapy genspider -t crawl spider_nombre dominio_nombreCrear comando Scraping Amazon crawler:
Por ejemplo, para crear un rastreador de Amazon llamado "amazonTop":
scrapy genspider -t crawl amzonTop amazon.comLas siguientes palabras son todo el código:
importar scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider):
name = 'amzonTop '
dominios_permitidos = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
devolver item
Rules es una tupla o lista que contiene objetos Rule. Una regla consta de parámetros como LinkExtractor, callback y follow.
A. LinkExtractor: Extractor de enlaces que compara direcciones URL mediante regex, XPath o CSS.
B. devolución de llamada: Una función de devolución de llamada para las direcciones URL extraídas, opcional.
C. seguir: Indica si las respuestas correspondientes a las direcciones URL extraídas seguirán siendo procesadas por las reglas. Verdadero significa que lo harán, y Falso significa que no lo harán.
3. Extracción de datos de productos de Amazon
3.1 Crear un crawler de Scraping Amazon
scrapy genspider -t crawl amazonTop2 amazon.comLa estructura del Código Araña:
3.2 Extraer las URL para paginar la lista de productos y los detalles de los productos.
A. Extraer todos los Asin y rangos de productos de la página de lista de productos, es decir, recuperar los Asin y rangos de los cajas azules en la imagen.
B. Extraer Asin para todos los colores y especificaciones de la página de detalles del producto, es decir, recuperar Asin del cajas verdesque incluyen a Asin de las cajas azules.
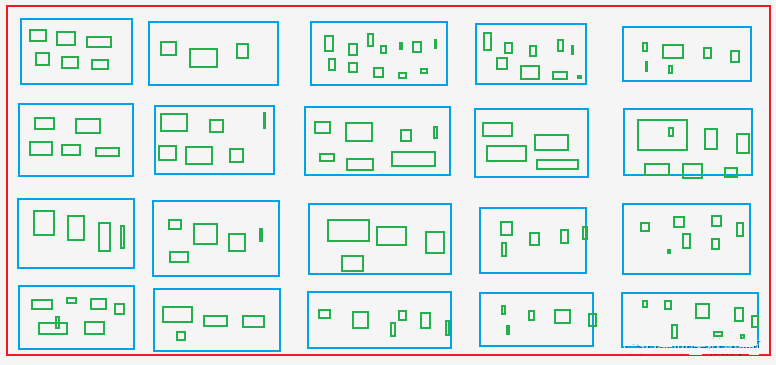
Las cajas verdes: Como las tallas X, M, L, XL y XXL para la ropa en los sitios de compras.
Archivo araña: amzonTop2.py
importar datetime
importar re
import time
from copy import deepcopy
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
dominios_permitidos = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
reglas = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
para asinDict en asin_list:
item = {}
if "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rango'] = pro_rank
item['ListaAsin'] = listaProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param respuesta:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?), "refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1]
excepto:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
excepto:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
lista_ASIN_todos_dict = eval(lista_ASIN_todos_str)
para asin_min_key, asin_min_value en list_ASIN_all_dict.items():
if asin_valor_min:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param respuesta:
:return:
"""
item = response.meta['news_info']
ASIN = item['segundoASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detalles = {}
for pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detalle",pro_detalle)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Barcos de"]/div//span//text()').extract()
# 物流方
prueba:
entrega = lista_de_envíos[-1]
excepto:
entrega = ""
vendedor = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
si vendedor == "":
vendedor = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if vendedor_enlace_str:
# vendedor_enlace = "https://www.amazon.com" + seller_link_str
# else:
# vendedor_enlace = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
probar:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
excepto:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
excepto:
precio = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Marca'] if "Marca" in clave_v else ''
if marca == ''
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif marca == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Marca: ", "").replace("Visite la", "").replace("Tienda", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Patrón'] if "Patrón" in clave_v else ""
if patrón == ""
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
Material #
probar:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
Forma #
shape = pro_detail['Shape'] if "Shape" in key_v else ""
if shape == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
# estilo
# cinco_puntos
cinco_puntos =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="nombre_color_variante"]//li').extract())
# variant_num =
# estilo
# fabricante
probar:
Fabricante = pro_detalle['Fabricante'] if "Fabricante" in str(pro_detalle) else " "
except:
Fabricante = ""
peso_artículo = pro_detail['Peso del artículo'] if "Peso" in str(pro_detail) else ''
product_dim = pro_detail['Dimensiones del producto'] if "Dimensiones del producto" in str(pro_detail) else ''
# material_producto
try:
product_material = pro_detail['Material']
except:
product_material = ''
# tipo_tejido
try:
tipo_tejido = pro_detalle['Tipo de tejido'] if "Tipo de tejido" in str(pro_detalle) else " "
except:
tipo_tejido = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
si lista_estrella:
try:
star_1 = star_list[0].strip()
except:
estrella_1 = 0
try:
star_2 = star_list[1].strip()
excepto:
estrella_2 = 0
try:
star_3 = star_list[2].strip()
excepto:
estrella_3 = 0
try:
star_4 = star_list[3].strip()
excepto:
estrella_4 = 0
try:
star_5 = star_list[4].strip()
excepto:
estrella_5 = 0
si no:
star_1 = 0
estrella_2 = 0
estrella_3 = 0
estrella_4 = 0
estrella_5 = 0
if "Fecha primera disponible" in str(pro_detalle):
data_first_available = pro_detail['Fecha Primera Disponible']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
si no:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# reviews_num, ratings_num
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['entrega']=entrega
item['vendedor']=vendedor
item['enlace_vendedor']=enlace_vendedor
item['enlace_marca']= enlace_marca
item['pic_link']=enlace_pic
item['title']=título
item['brand']=marca
item['star']=estrella
item['precio']=precio
item['color']=color
item['patrón']=patrón
item['material']=material
item['shape']=forma
item['cinco_puntos']=cinco_puntos
item['tamaño_num']=tamaño_num
item['color_num']=color_num
item['Fabricante']=Fabricante
item['peso_artículo']=peso_artículo
item['product_dim']=dim_producto
item['material_producto']=material_producto
item['tipo_tejido']=tipo_tejido
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['tiempo_desechos']=tiempo_desechos
item['enlace_opiniones']=enlace_opiniones
item['tamaño']=tamaño
item['datos_primeros_disponibles']=datos_primeros_disponibles
producir elemento
Cuando recopile una cantidad considerable de datos, cambie la IP y gestione el reconocimiento de captchas.
4. Métodos para descargar middlewares
4.1 process_request(self, request, spider)
A. Llamada cuando cada solicitud pasa por el middleware de descarga.
B. Devolver None: Si no se devuelve ningún valor (o devolver None explícitamente), el objeto de solicitud se pasa al descargador o a otros métodos process_request de menor peso.
C. Devolución del objeto Respuesta: No se realizan más peticiones y se devuelve la respuesta al motor.
D. Devuelve el objeto Solicitud: El objeto request se pasa al planificador a través del motor. Se omiten otros métodos process_request con menor peso.
4.2 process_response(self, request, response, spider)
A. Llamada cuando el descargador completa la petición HTTP y pasa la respuesta al motor.
B. Respuesta de retorno: Pasada a la araña para su procesamiento o al método process_response de otro middleware de descarga con menor peso.
C. Devuelve el objeto Solicitud: Pasado al planificador a través del motor para posteriores peticiones. Se omiten otros métodos process_request con menor peso.
D. Configure la activación del middleware y establezca los valores de ponderación en settings.py. Los pesos más bajos tienen prioridad.
middlewares.py
4.3 Configurar IP proxy
clase ProxyMiddleware(objeto):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True
devolver solicitud
clase AmazonspiderDownloaderMiddleware:
# No es necesario definir todos los métodos. Si un método no está definido,
# scrapy actúa como si el middleware downloader no modifica el
# objetos pasados.
@método_class
def from_crawler(cls, crawler):
# Este método es utilizado por Scrapy para crear sus arañas.
s = cls()
crawler.signals.connect(s.araña_abierta, signal=señales.araña_abierta)
devuelve s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'la cookie pegada desde el navegador'
# transferencia de cookies_str a cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def procesar_respuesta(self, petición, respuesta, araña):
return respuesta
def procesar_excepción(self, petición, excepción, araña):
pass
def araña_abierta(self, araña):
spider.logger.info('Araña abierta: %s' % spider.name)
4.5 Visite Raspado Código de verificación de Amazon para desbloquear desde Amazon.
def captcha_verfiy(nombre_img):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'es'])
# reader = easyocr.Reader(['es'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
si resultado:
result = result.replace(' ', '')
devolver resultado
def descargar_captcha(captcha_url):
# descargar-captcha
response = requests.get(captcha_url, stream=True)
prueba
with open(r'./captcha.png', 'wb') as logFile:
for chunk in respuesta:
logFile.write(chunk)
logFile.close()
print("¡Descarga realizada!")
excepto Exception como e:
print("¡Error en el registro de descarga!")
clase AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=señales.spider_opened)
devolver s
def process_request(self, request, spider):
return None
def procesar_respuesta(self, petición, respuesta, araña):
# print(respuesta.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=cabeceras)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//entrada[@nombre='amzn-r']/@valor"))
descargar_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=cabeceras)
if "Lo sentimos, tenemos que asegurarnos de que no eres un robot" not in str(resp.text):
response2 = HtmlResponse(url=url_nueva, headers=headers,body=resp.text, encoding='utf-8')
if "Lo sentimos, tenemos que asegurarnos de que no eres un robot" not in str(response2.text):
return respuesta2
else:
return request
si no
return response
def procesar_excepción(self, petición, excepción, araña):
pass
def araña_abierta(self, araña):
spider.logger.info('Araña abierta: %s' % spider.name)
Eso es todo el código sobre Scraping datos de Amazon.
Si cualquier ayuda por favor deje Soporte OkeyProxy saber.
Proveedores de proxy recomendados: Okeyproxy - Top 5 Socks5 Proxy Provider con 150M+ Proxies Residenciales de 200+ Países. Prueba gratuita de 1 GB de proxies residenciales ahora!