
インターネット上のデータの爆発的な増加に伴い、オンライン情報を収集、処理、分析する必要性がこれまで以上に高まっている。そこで、2つの強力なテクニックが登場する。ウェブクローリング そして ウェブスクレイピング.これらの用語はしばしば同じ意味で使われますが、同じではありません。商品価格の収集であれ、競合サイトの監視であれ、検索インデックスの構築であれ、これらの方法はデータ収集を大規模に自動化するのに役立ちます。
同じ?ウェブデータ収集に関するさまざまな用語
ウェブ・クローリングとは何か?
ウェブクローリングとは、インターネットを自動的に閲覧し、複数のページにまたがるURLやリンクを発見するプロセスのことです。グーグルのような検索エンジンが新しいウェブページを発見し、インデックスを作成する方法と考えてください。
🕷 例:
スパイダーやボットとしても知られるウェブクローラーは、ウェブページからスタートし、内部/外部リンクをすべてたどってより多くのページを発見する。これにより、URLを収集することができますが、必ずしも特定のデータをダウンロードしたり抽出したりするわけではありません。
典型的な使用例
- 検索エンジン用インデックスの構築
- ウェブサイトの変更を大規模に監視
- 自分のサイトのリンク切れを検出する
ウェブスクレイピングとは何か?
ウェブ・スクレイピング とは、1つまたは複数のウェブページから特定のデータの断片を抽出するプロセスである。スクレイパーは、単にリンクを発見するのではなく、製品名、価格、連絡先情報などのコンテンツをターゲットとし、それを次のようなフォーマットに変換する。 CSV、JSON等々。
🧲 例:
そうかもしれない。 ウォルマートから商品価格をかき集める などのeコマースサイト、キャリアポータルの求人情報、ソーシャルメディアの投稿統計など。
典型的な使用例
- 価格比較ツール
- リードジェネレーション(ディレクトリから連絡先を集める)
- 市場調査(レビューや評価を集める)
ウェブクローリングとウェブスクレイピングの比較ウェブスクレイピング:主な違い
クローラーがウェブをマッピングするのに対し、スクレイパーは重要な情報をゼロから探し出す。
| アスペクト | ウェブ・クローリング | ウェブ・スクレイピング |
|---|---|---|
| 主要目標 | ウェブページの発見とインデックス | 構造化データの抽出 |
| オペレーション | リンクを再帰的にたどる | 特定のデータを解析し、引き出す |
| 出力 | ウェブページ一覧 | 構造化データ(CSV、JSONなど) |
| 複雑さ | ページごとのロジックはシンプルだが、規模が重要 | ページごとの複雑な解析ロジック |
| ツールとライブラリ | Scrapy(クローラー)、Heritrix、Apache Nutch、Requestsなど。 | BeautifulSoup、Selenium、lxml、Requestsなど。 |
| ターゲット | ウェブサイト全体 | 個々のページまたはページ要素 |
| 使用例 | グーグル、ニュース記事をインデックス化 | 記事のタイトルと著者の取得 |
多くの場合、両方の技術が併用される。クローラーはページを見つけ、スクレイパーはそこからデータを抽出する。
Pythonコードスニペット:ウェブクローリング対スクレイピングスクレイピング
クローリングとスクレイピングのための最小限のPythonコード・スニペットを見てみよう。
Pythonでウェブクローリングを行う方法
Pythonは、以下のようなライブラリでウェブクローリングを簡単にします。 スクラップ または リクエスト + ビューティフル・スープ.
例Scrapyを使ったシンプルなウェブクローラ
#インストール: pip install scrapy
インポート scrapy
class SimpleCrawler(scrapy.Spider):
name = "simple_crawler"
start_urls = ["https://example.com"] です。
def parse(self, response):
# ページタイトルを表示する
title = response.css('title::text').get()
yield {'url': response.url, 'title': title}.
# すべての内部リンクをたどる
for href in response.css('a::attr(href)').getall():
if href.startswith('/'):
yield response.follow(href, callback=self.parse)例Requests + BeautifulSoupを使ったシンプルなWebクローラー
インポートリクエスト
from bs4 import BeautifulSoup
from urllib.parse import urljoin
visited = set()
start_url = "https://example.com"
def crawl(url):
if url in visited:
return
visited.add(url)
を試す:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print("Crawling:", url)
for link in soup.find_all('a', href=True):
full_url = urljoin(url, link['href'])
クロール(full_url)
except Exception as e:
print("Failed to crawl:", url, "Reason:", e)
クロール(start_url) 注: 大規模なウェブサイトを素早くクロールすると、IPフラグが立ち、ブロックされる可能性があります。そのため ローテーションIPプロキシ.
PythonでWeb Scarpingを行う方法
PythonでのWebスクレイピングは、自動化されたスクリプトを使用してWebサイトからデータを抽出することを含む。このタスクのための最も人気のあるライブラリの1つは ビューティフル・スープと併用されることが多い。 リクエスト.
例えば、特定のtag、属性、クラスを検索し、商品名、価格、見出しなどの有用な情報を抽出することができます。
例ページからの商品タイトルのスクレイピング
インポートリクエスト
from bs4 import BeautifulSoup
url = "https://example.com/products"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
for product in soup.select(".product"):
name = product.select_one(".name").get_text(strip=True)
price = product.select_one(".price").get_text(strip=True)
print({"name": name, "price": price})セレクタやXPathを使って、テーブルやリスト、カスタムHTML要素からデータを取得することができます。
ヒント ウェブスクレイピングやクローリングは一般的に合法ですが、一部のウェブサイトでは、利用規約やサイト内でそのような行為を禁止しています。 robots.txt ファイルを使用してください。あなたのボットでどのパスが許可されているか、または許可されていないか、常に確認してください。
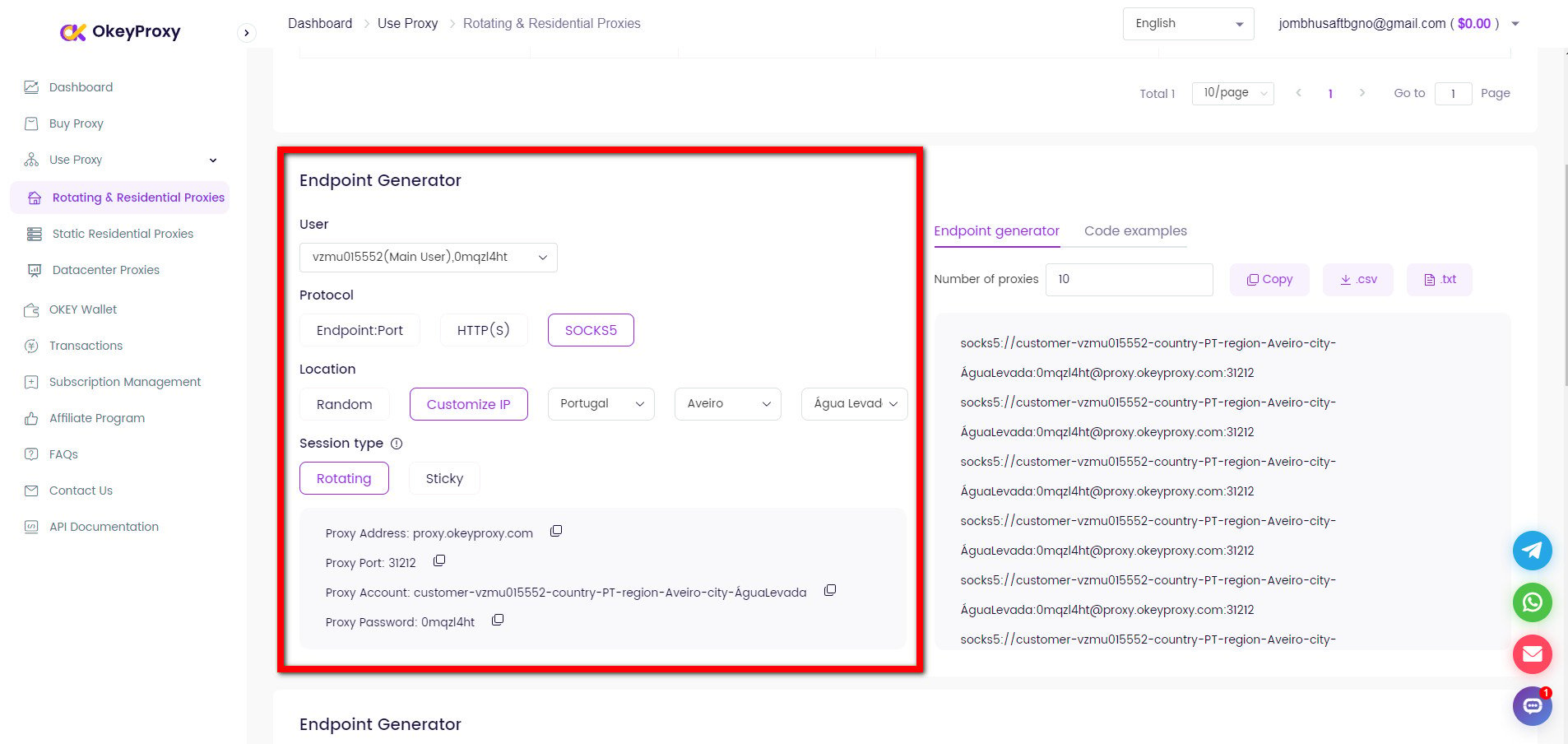
IPプロキシを利用してIPブロックを解除する
あなたのIPアドレスから多くのリクエストを実行すると、CAPTCHAのようなボット対策やウェブサイトからの全面的な禁止を引き起こす可能性があります。信頼性とスピードを維持するために、何百万もの実際のIPアドレスを自動的に切り替えることができるIPプロキシの使用を追加することを検討してください。
を使用するようにHTTPクライアントを設定するだけです。 オッケープロキシー を新しいIPアドレスに変更するか、IPアドレスをローテーションする:
ウェブクローリング/スクレイピングの制限を回避するための新しいIPへの変更
プロキシ = {
"http":"http://username:[email protected]:1234"、
「https":"http://username:[email protected]:1234"、
}
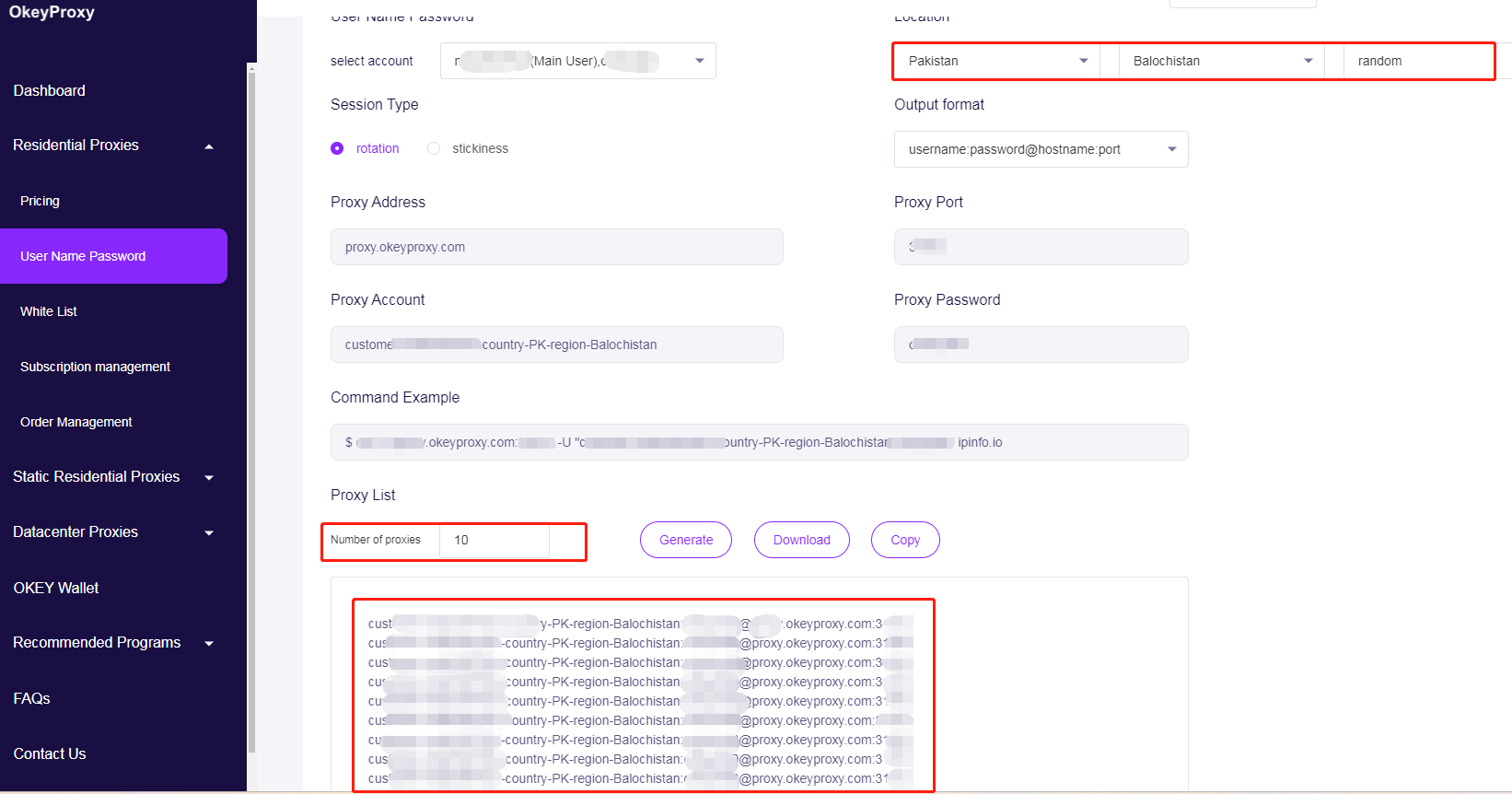
resp = requests.get(url, headers=headers, proxies=proxies, timeout=10)Webクローリング/スクレイピングの制限を回避するためにプロキシIPをローテーションする
# プロキシプール - プロキシIPで置き換える
プロキシプール = [
"http://username1:[email protected]:1234"、
"http://username2:[email protected]:1234"、
"http://username3:[email protected]:1234"、
"http://username4:[email protected]:1234"
]
# プールからランダムにプロキシを選択し、検証する
def rotate_proxy():
while True:
proxy = random.choice(PROXY_POOL)
if check_proxy(proxy):
プロキシを返す
else:
print(f "Proxy {proxy} is not available, trying another...")
PROXY_POOL.remove(プロキシ)
raise Exception("有効なプロキシがプールに残っていません。")
# テストリクエストでプロキシが動作しているかチェックする
def check_proxy(proxy):
try:
test_url = "https://httpbin.org/ip"
response = requests.get(test_url, proxies={"http": proxy}, timeout=10)
return response.status_code == 200
ただし
return Falseを持っている。 高品質家庭用代理サービスそのため、禁止や拒否を心配することなく、安全にウェブクローラやスクレーパーを大規模に実行することができる。
データ・クローリングとスクレイピングは何に使われるのか?
オンラインで利用可能な膨大な量のデータから貴重な洞察を引き出すために広く使用されているウェブクローリングとウェブスクレイピングは、今日のデータ経済を支える不可欠なツールとなっている。
一方では、企業はウェブスクレイピングを活用して、センチメント分析のためにカスタマーレビュー、フォーラムへの投稿、ソーシャルメディアでの会話を収集している。消費者センチメント分析にとどまらず、データクローリングはマーケットインテリジェンスプラットフォームを強化し、ウェブスクレイピングを含む代替データ市場は2023年に49億米ドルと評価され、今後さらに成長すると予測されている。 年率28% は2032年まで続く。実際、2024年の企業データ予算のうち42.0%がウェブデータの取得と処理に割り当てられており、ウェブデータの重要な役割が浮き彫りになっている。 データに基づく意思決定.小売業界では、59%の小売業者が競争価格監視ツール(多くの場合、自動スクレイピングに基づく)を使用しており、ダイナミックプライシング戦略を最適化し、収益を高めている。
一方、データクローリングとスクレイピングの主な用途のひとつは、次のようなものだ。 AIと機械学習 のイニシアチブをとっており、65.0%の組織がウェブスクレイピングを活用してモデルを構築している。例えば、Common Crawlの2024年4月のアーカイブは、27億のウェブページ(386TiBのコンテンツ)を収集し、次のような役割を果たしている。 主要な自然言語処理モデル訓練のための基礎データセット.そのほか、学術研究者や、2億500万件以上の学術論文をインデックス化したSemantic Scholarのようなプラットフォームも、膨大な文献をインデックス化するためにウェブクローラーを使っている。また、SEOやマーケティングチームは、サイト監査、バックリンク分析、競合調査にウェブクローリングを利用している。
結論
ウェブクローリングはページを発見して訪問することであり、ウェブスクレイピングはデータを抽出することである。Pythonは、開発者でなくてもこの2つの技術にアクセスできるようにする。
責任あるクローリング、ターゲットを絞ったスクレイピング、信頼性の高い管理を組み合わせることで、次のようなことが可能になります。 スクレイピング&クローリングプロキシこれにより、アナリティクス、機械学習モデル、ビジネス・インサイトを促進する強力なデータ・パイプラインを、中断することなく構築できます。
ウェブクローリングとウェブスクレイピングを強化しませんか?まずは OkeyProxyの試用 今すぐ、シームレスで大規模なデータ収集を体験してください!


一流のSocks5/http(s)プロキシ・サービス
- スケーラブルなプラン静的プラン居住者用プロキシのローテーション
- シームレスな統合:Win/iOS/Android/Linux
- 高いセキュリティ:アンチディテクトブラウザ、エミュレータ、スクレーパーなどに最適。
- 信頼性の高いパフォーマンス:高速転送と低遅延

