
Avec l'explosion des données sur Internet, la nécessité de collecter, de traiter et d'analyser les informations en ligne est devenue plus importante que jamais. C'est là que deux techniques puissantes entrent en jeu.exploration du web et scraping web. Bien que ces termes soient souvent utilisés de manière interchangeable, ils ne sont pas identiques. Qu'il s'agisse de recueillir les prix des produits, de surveiller les sites web des concurrents ou de créer un index de recherche, ces méthodes peuvent vous aider à automatiser la collecte de données à grande échelle.
Les mêmes ? Les différents termes de la collecte de données sur le web
Qu'est-ce que l'exploration du Web ?
L'exploration du web est le processus qui consiste à parcourir automatiquement l'internet et à découvrir des URL ou des liens sur plusieurs pages. C'est ainsi que les moteurs de recherche comme Google trouvent et indexent de nouvelles pages web.
🕷 Exemple :
Un robot d'exploration du web, également appelé "spider" ou "bot", part d'une page web et suit tous les liens internes/externes pour découvrir d'autres pages. Cela lui permet de collecter des URL, mais pas nécessairement de télécharger ou d'extraire des données spécifiques.
Cas d'utilisation typiques :
- Construire un index de moteur de recherche
- Suivi des modifications du site web à grande échelle
- Détecter les liens brisés sur votre propre site
Qu'est-ce que le "Web Scraping" ?
Récupération de données sur Internet est le processus d'extraction d'éléments de données spécifiques à partir d'une ou de plusieurs pages web. Au lieu de se contenter de découvrir des liens, les scrapers ciblent des contenus tels que des noms de produits, des prix ou des informations de contact et les formatent en CSV, JSON, etc.
🧲 Exemple :
Vous pourriez récupérer les prix des produits chez Walmart ou d'un autre site de commerce électronique, les offres d'emploi d'un portail de carrière, les statistiques des messages sur les médias sociaux, etc.
Cas d'utilisation typiques :
- Outils de comparaison des prix
- Génération de leads (collecte de contacts à partir d'annuaires)
- Étude de marché (collecte d'avis, d'évaluations)
Web Crawling Vs. Récupération de données sur le web : Principales différences
Alors que les crawlers cartographient le web, les scrapers se concentrent sur les informations importantes.
| Aspect | L'exploration du Web | Récupération de données sur le Web |
|---|---|---|
| Objectif principal | Découvrir et indexer des pages web | Extraire des données structurées |
| Fonctionnement | Suit les liens de manière récursive | Analyse et extrait des données spécifiques |
| Sortie | Liste des pages web | Données structurées (CSV, JSON, etc.) |
| Complexité | Une logique par page plus simple, mais l'échelle est importante | Logique d'analyse complexe par page |
| Outils et bibliothèques | Scrapy (Crawler), Heritrix, Apache Nutch, Requests, etc. | BeautifulSoup, Selenium, lxml, Requests, etc. |
| Cible | Sites web entiers | Pages individuelles ou éléments de page |
| Exemple d'utilisation | Indexation des articles de presse par Google | Obtenir les titres et les auteurs des articles |
Dans de nombreux cas, les deux techniques sont utilisées conjointement. Un crawler trouve des pages et un scraper en extrait les données.
Extraits de code Python : Web Crawling Vs. Scraping
Examinons des extraits de code Python minimaux pour le crawling et le scraping.
Comment faire du web crawling en Python
Python facilite l'exploration du web grâce à des bibliothèques telles que Ferraille ou Demandes + BeautifulSoup.
Exemple : Crawler Web simple utilisant Scrapy
Installation # : pip install scrapy
importer scrapy
classe SimpleCrawler(scrapy.Spider) :
name = "simple_crawler"
start_urls = ["https://example.com"]
def parse(self, response) :
# Impression du titre de la page
title = response.css('title::text').get()
yield {'url' : response.url, 'title' : title}
# Suivre tous les liens internes
for href in response.css('a::attr(href)').getall() :
if href.startswith('/') :
yield response.follow(href, callback=self.parse)Exemple : Crawler Web simple utilisant Requests + BeautifulSoup
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
visité = set()
start_url = "https://example.com"
def crawl(url) :
si url dans visited :
retour
visited.add(url)
try :
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print("Crawling :", url)
for link in soup.find_all('a', href=True) :
full_url = urljoin(url, link['href'])
crawl(full_url)
except Exception as e :
print("Failed to crawl :", url, "Reason :", e)
crawl(start_url) Remarque : L'exploration rapide de grands sites web peut entraîner le signalement et le blocage de votre IP. C'est pourquoi vous devez Proxies IP tournants.
Comment faire du scarping web en Python
Le web scraping en Python consiste à extraire des données de sites web à l'aide de scripts automatisés. L'une des bibliothèques les plus populaires pour cette tâche est BeautifulSoup, souvent utilisé en combinaison avec Demandes.
Par exemple, vous pouvez localiser des tag, des attributs ou des classes spécifiques et extraire des informations utiles telles que les noms de produits, les prix ou les titres.
Exemple : Récupérer les titres de produits d'une page
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
for product in soup.select(".product") :
name = product.select_one(".name").get_text(strip=True)
prix = produit.select_one(".prix").get_text(strip=True)
print({"nom" : nom, "prix" : prix})Vous pouvez utiliser des sélecteurs ou XPath pour extraire des données de tableaux, de listes ou d'éléments HTML personnalisés.
Conseil : Bien que le web scraping et le crawling soient couramment légaux, certains sites web interdisent ce type de comportement dans leurs conditions de service ou dans leur site web. robots.txt fichiers. Vérifiez toujours quels chemins sont autorisés ou non pour votre robot.
Rester débloqué sans interdiction d'IP à l'aide d'un proxy IP
L'exécution de nombreuses requêtes à partir de votre adresse IP peut déclencher des défenses anti-bots telles que les CAPTCHA ou l'interdiction pure et simple d'accès à des sites web. Pour maintenir la fiabilité et la vitesse, envisagez d'ajouter l'utilisation d'un proxy IP, qui peut automatiquement basculer entre des millions d'adresses IP réelles.
Il suffit de configurer votre client HTTP pour qu'il utilise OkeyProxy avec une nouvelle adresse IP ou une rotation des adresses IP :
Passer à de nouvelles adresses IP pour éviter les limites du crawling/scraping sur le web
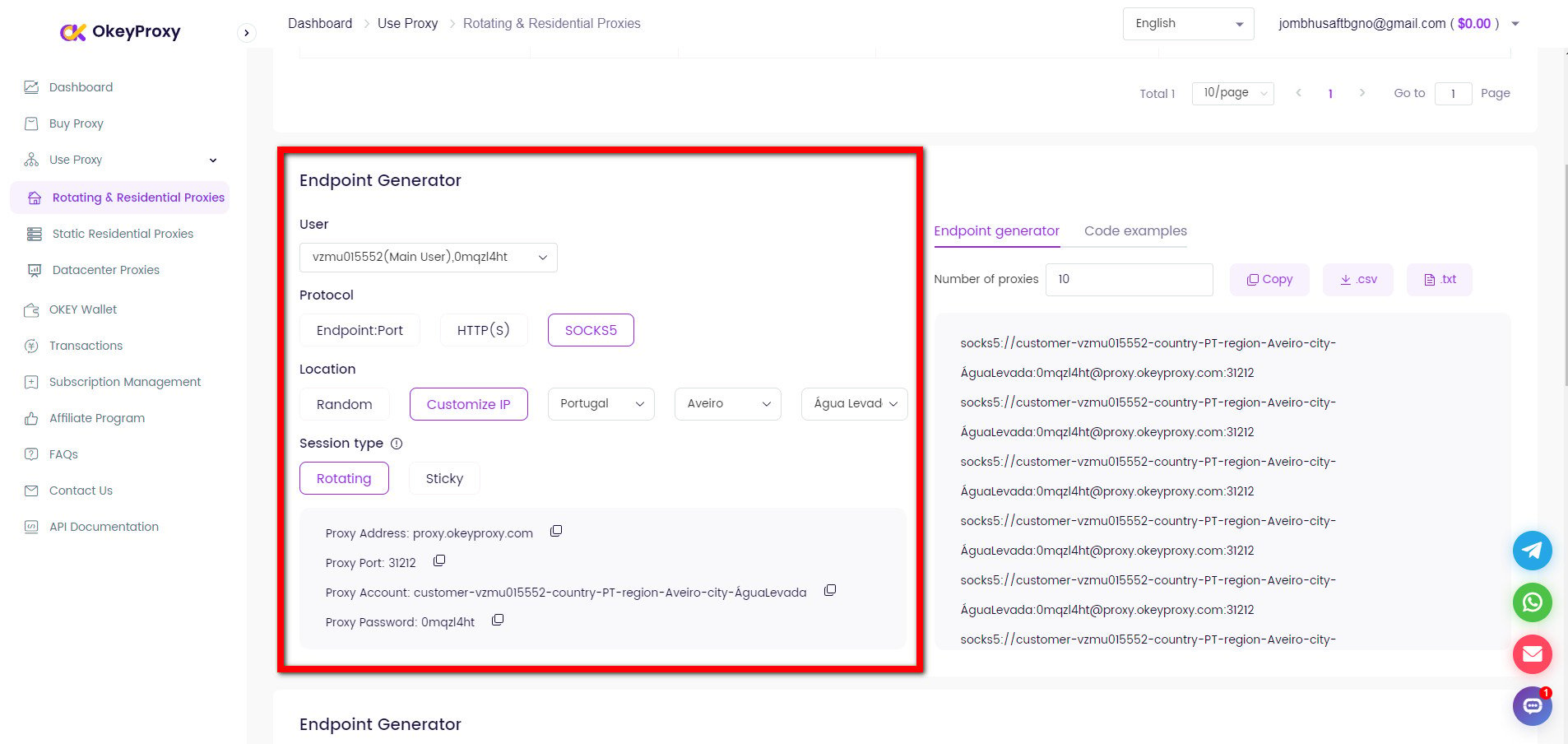
proxies = {
"http" : "http://username:[email protected]:1234",
"https" : "http://username:[email protected]:1234",
}
resp = requests.get(url, headers=headers, proxies=proxies, timeout=10)Rotation des IP proxy pour éviter les limites du crawling/scraping sur le Web
# Proxy pool - remplacer par vos IP proxy
PROXY_POOL = [
"http://username1:[email protected]:1234",
"http://username2:[email protected]:1234",
"http://username3:[email protected]:1234",
"http://username4:[email protected]:1234"
]
# Sélection aléatoire et validation d'un proxy dans le pool
def rotate_proxy() :
while True :
proxy = random.choice(PROXY_POOL)
if check_proxy(proxy) :
return proxy
else :
print(f "Le proxy {proxy} n'est pas disponible, essayez-en un autre...")
PROXY_POOL.remove(proxy)
raise Exception("Il n'y a plus de proxy valide dans le pool.")
# Vérifier qu'un proxy fonctionne en effectuant une requête de test
def check_proxy(proxy) :
try :
test_url = "https://httpbin.org/ip"
response = requests.get(test_url, proxies={"http" : proxy}, timeout=10)
return response.status_code == 200
except :
return FalseAvec un un service de procuration résidentielle de haute qualitévous pouvez utiliser en toute sécurité des robots d'indexation ou des scanners à grande échelle sans vous soucier des interdictions ou des rejets.
À quoi servent le crawling et le scraping de données ?
Largement utilisés pour extraire des informations précieuses des vastes quantités de données disponibles en ligne, le crawling et le scraping du web sont devenus des outils indispensables à l'économie des données d'aujourd'hui.
D'une part, les organisations utilisent le web scraping pour collecter les avis des clients, les messages des forums et les conversations sur les médias sociaux pour l'analyse des sentiments. Au-delà de l'analyse du sentiment des consommateurs, le crawling de données alimente les plateformes d'intelligence économique, que le marché des données alternatives, qui comprend le web scraping, a été évalué à 4,9 milliards USD en 2023 et devrait croître à un taux de taux annuel de 28% jusqu'en 2032. En fait, 42,0% des budgets de données des entreprises en 2024 ont été alloués spécifiquement à l'acquisition et au traitement des données web, ce qui souligne le rôle essentiel de ces données dans la lutte contre le terrorisme. la prise de décision fondée sur les données. Dans le secteur de la vente au détail, 59% des détaillants utilisent des outils de surveillance des prix concurrentiels - souvent basés sur le scraping automatisé - afin d'optimiser les stratégies de tarification dynamique et d'augmenter le chiffre d'affaires.
D'autre part, l'une des principales applications du crawling et du scraping de données est l'alimentation en énergie des systèmes d'information. IA et apprentissage automatique avec 65,0% des organisations qui utilisent le web scraping pour alimenter leurs modèles. Par exemple, l'archive d'avril 2024 de Common Crawl a recueilli 2,7 milliards de pages web (386 TiB de contenu), servant de ensemble de données fondamentales pour l'entraînement des principaux modèles NLP. En outre, les chercheurs universitaires et les plateformes telles que Semantic Scholar, qui ont indexé plus de 205 millions d'articles scientifiques, ont également utilisé des robots d'indexation pour indexer de vastes corpus de documents. Enfin, les équipes de référencement et de marketing utilisent les robots d'indexation pour l'audit des sites, l'analyse des liens retour et l'étude de la concurrence.
Conclusion
Le web crawling consiste à découvrir et visiter des pages ; le web scraping consiste à extraire des données. Python rend ces deux techniques accessibles, même pour les non-développeurs.
En combinant le crawling responsable, le scraping ciblé et une gestion fiable de l'information, le site web de l proxies pour le scraping et le crawlingVous pouvez créer des pipelines de données puissants qui alimentent les analyses, les modèles d'apprentissage automatique et les informations commerciales, sans interruption.
Prêt à intensifier vos activités de recherche et de récupération de données sur le web ? Commencez avec un procès d'OkeyProxy dès aujourd'hui et faites l'expérience d'une collecte de données à grande échelle en toute transparence !


Service Proxy Socks5/Http(s) de premier ordre
- Plans évolutifs : Statique/Rotation des procurations résidentielles
- Intégration transparente : Win/iOS/Android/Linux
- Haute sécurité : Idéal pour la détection des navigateurs, des émulateurs, des scrapeurs, etc.
- Performance fiable : Transfert rapide et faible latence

