
Angesichts der explosionsartigen Zunahme von Daten im Internet ist die Notwendigkeit, Online-Informationen zu sammeln, zu verarbeiten und zu analysieren, wichtiger denn je. Hier kommen zwei leistungsstarke Techniken ins Spiel.Web-Crawling und Web-Scraping. Obwohl diese Begriffe oft synonym verwendet werden, sind sie nicht dasselbe. Ganz gleich, ob Sie Produktpreise erfassen, Websites von Mitbewerbern überwachen oder einen Suchindex erstellen, mit diesen Methoden können Sie die Datenerfassung in großem Umfang automatisieren.
Dasselbe? Die verschiedenen Begriffe für die Webdatenerfassung
Was ist Web Crawling?
Web-Crawling ist der Prozess des automatischen Durchsuchens des Internets und der Entdeckung von URLs oder Links auf mehreren Seiten. Stellen Sie sich vor, wie Suchmaschinen wie Google neue Webseiten finden und indizieren.
🕷 Beispiel:
Ein Web-Crawler, auch Spider oder Bot genannt, geht von einer Webseite aus und folgt allen internen/externen Links, um weitere Seiten zu entdecken. Dadurch kann er URLs sammeln, aber nicht unbedingt bestimmte Daten herunterladen oder extrahieren.
Typische Anwendungsfälle:
- Aufbau eines Suchmaschinenindexes
- Überwachung von Website-Änderungen im großen Maßstab
- Erkennung fehlerhafter Links auf Ihrer eigenen Website
Was ist Web Scraping?
Web-Scraping ist der Prozess des Extrahierens bestimmter Daten aus einer oder mehreren Webseiten. Anstatt nur Links zu entdecken, suchen Scraper gezielt nach Inhalten wie Produktnamen, Preisen oder Kontaktinformationen und formatieren sie in CSV, JSON, usw.
🧲 Beispiel:
Sie könnten Produktpreise von Walmart abgreifen oder einer anderen E-Commerce-Website, Stellenangeboten eines Karriereportals, Statistiken über Beiträge in sozialen Medien usw.
Typische Anwendungsfälle:
- Preisvergleichs-Tools
- Lead-Generierung (Sammeln von Kontakten aus Verzeichnissen)
- Marktforschung (Einholung von Rezensionen, Bewertungen)
Web Crawling vs. Web Scraping. Web Scraping: Hauptunterschiede
Während Crawler das Web abbilden, konzentrieren sich Scraper auf die wirklich wichtigen Informationen.
| Aspekt | Web Crawling | Web-Scraping |
|---|---|---|
| Primäre Zielsetzung | Webseiten entdecken und indexieren | Strukturierte Daten extrahieren |
| Operation | Folgt den Links rekursiv | Analysiert und ruft spezifische Daten ab |
| Ausgabe | Liste der Webseiten | Strukturierte Daten (CSV, JSON, usw.) |
| Komplexität | Einfachere Logik pro Seite, aber der Umfang ist wichtig | Komplexe Parsing-Logik pro Seite |
| Tools & Bibliotheken | Scrapy (Crawler), Heritrix, Apache Nutch, Requests, usw. | BeautifulSoup, Selenium, lxml, Requests, usw. |
| Ziel | Vollständige Websites | Einzelne Seiten oder Seitenelemente |
| Beispiel Verwendung | Google indexiert Nachrichtenartikel | Titel und Autoren von Artikeln ermitteln |
In vielen Fällen werden beide Techniken zusammen eingesetzt. Ein Crawler findet Seiten, und ein Scraper extrahiert die Daten von ihnen.
Python-Code-Schnipsel: Web Crawling Vs. Scraping
Sehen wir uns minimale Python-Code-Schnipsel für Crawling und Scraping an.
Web Crawling in Python durchführen
Python macht Web-Crawling einfach mit Bibliotheken wie Scrapy oder Anfragen an + BeautifulSoup.
Beispiel: Einfacher Web Crawler mit Scrapy
# installieren: pip install scrapy
scrapy importieren
Klasse SimpleCrawler(scrapy.Spider):
name = "simple_crawler"
start_urls = ["https://example.com"]
def parse(self, response):
# Drucke den Seitentitel
title = response.css('title::text').get()
yield {'url': response.url, 'title': title}
# Alle internen Links verfolgen
for href in response.css('a::attr(href)').getall():
if href.startswith('/'):
yield response.follow(href, callback=self.parse)Beispiel: Einfacher Web Crawler mit Requests + BeautifulSoup
Anfragen importieren
von bs4 importieren BeautifulSoup
from urllib.parse import urljoin
besucht = gesetzt()
start_url = "https://example.com"
def crawl(url):
if url in visited:
return
visited.add(url)
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print("Crawling:", url)
for link in soup.find_all('a', href=True):
full_url = urljoin(url, link['href'])
crawl(full_url)
except Exception as e:
print("Failed to crawl:", url, "Reason:", e)
crawl(start_url) Anmerkung: Das schnelle Crawlen großer Websites kann dazu führen, dass Ihre IP-Adresse markiert und blockiert wird. Deshalb brauchen Sie rotierende IP-Proxys.
Wie man Web Scarping in Python durchführt
Web Scraping in Python beinhaltet das Extrahieren von Daten aus Websites mithilfe automatisierter Skripte. Eine der beliebtesten Bibliotheken für diese Aufgabe ist BeautifulSoupoft in Kombination mit Anfragen an.
So können Sie beispielsweise bestimmte tags, Attribute oder Klassen ausfindig machen und nützliche Informationen wie Produktnamen, Preise oder Überschriften extrahieren.
Beispiel: Einlesen von Produkttiteln von einer Seite
Anfragen importieren
von bs4 importieren BeautifulSoup
url = "https://example.com/products"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
for produkt in soup.select(".produkt"):
name = produkt.select_one(".name").get_text(strip=True)
preis = produkt.select_one(".preis").get_text(strip=True)
print({"name": name, "preis": preis})Sie können Selektoren oder XPath verwenden, um Daten aus Tabellen, Auflistungen oder benutzerdefinierten HTML-Elementen abzurufen.
Tipp: Während Web Scraping und Crawling im Allgemeinen legal sind, verbieten einige Websites dieses Verhalten in ihren Nutzungsbedingungen oder in ihren robots.txt Dateien. Prüfen Sie immer, welche Pfade für Ihren Bot erlaubt oder nicht erlaubt sind.
Ungesperrt bleiben ohne IP-Sperre mit IP-Proxy
Viele Anfragen von Ihrer IP-Adresse aus können Anti-Bot-Verteidigungsmaßnahmen wie CAPTCHAs auslösen oder den Zugriff auf Websites ganz unterbinden. Um die Zuverlässigkeit und Geschwindigkeit aufrechtzuerhalten, sollten Sie die Verwendung eines IP-Proxys in Erwägung ziehen, der automatisch zwischen Millionen von echten IP-Adressen umschalten kann.
Konfigurieren Sie einfach Ihren HTTP-Client für die Verwendung von OkeyProxy mit einer neuen IP-Adresse oder rotierenden IP-Adressen:
Wechsel zu neuen IPs, um Web Crawling/Scraping-Beschränkungen zu vermeiden
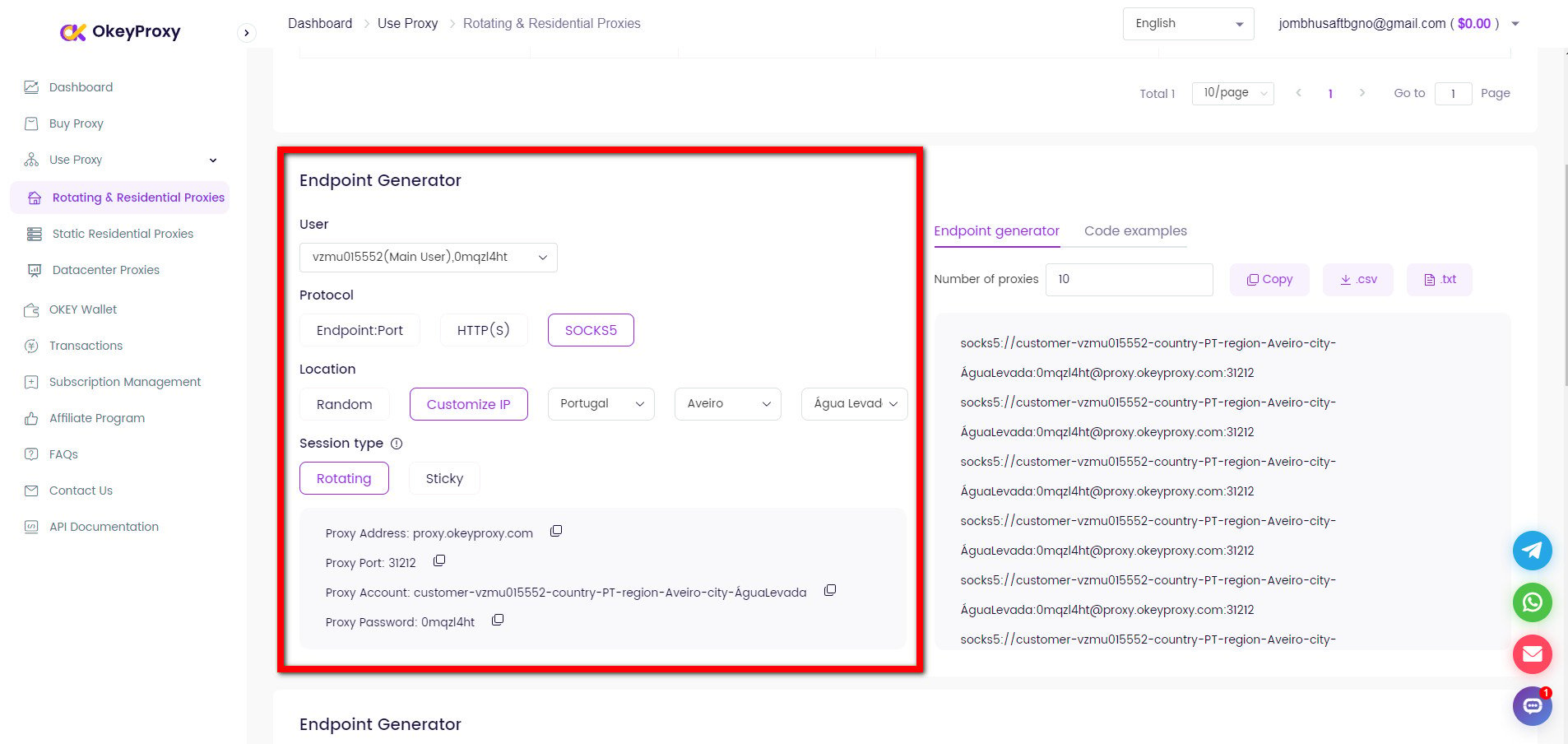
proxies = {
"http": "http://username:[email protected]:1234",
"https": "http://username:[email protected]:1234",
}
resp = requests.get(url, headers=headers, proxies=proxies, timeout=10)Proxy-IPs rotieren, um Web-Crawling/Scraping-Beschränkungen zu vermeiden
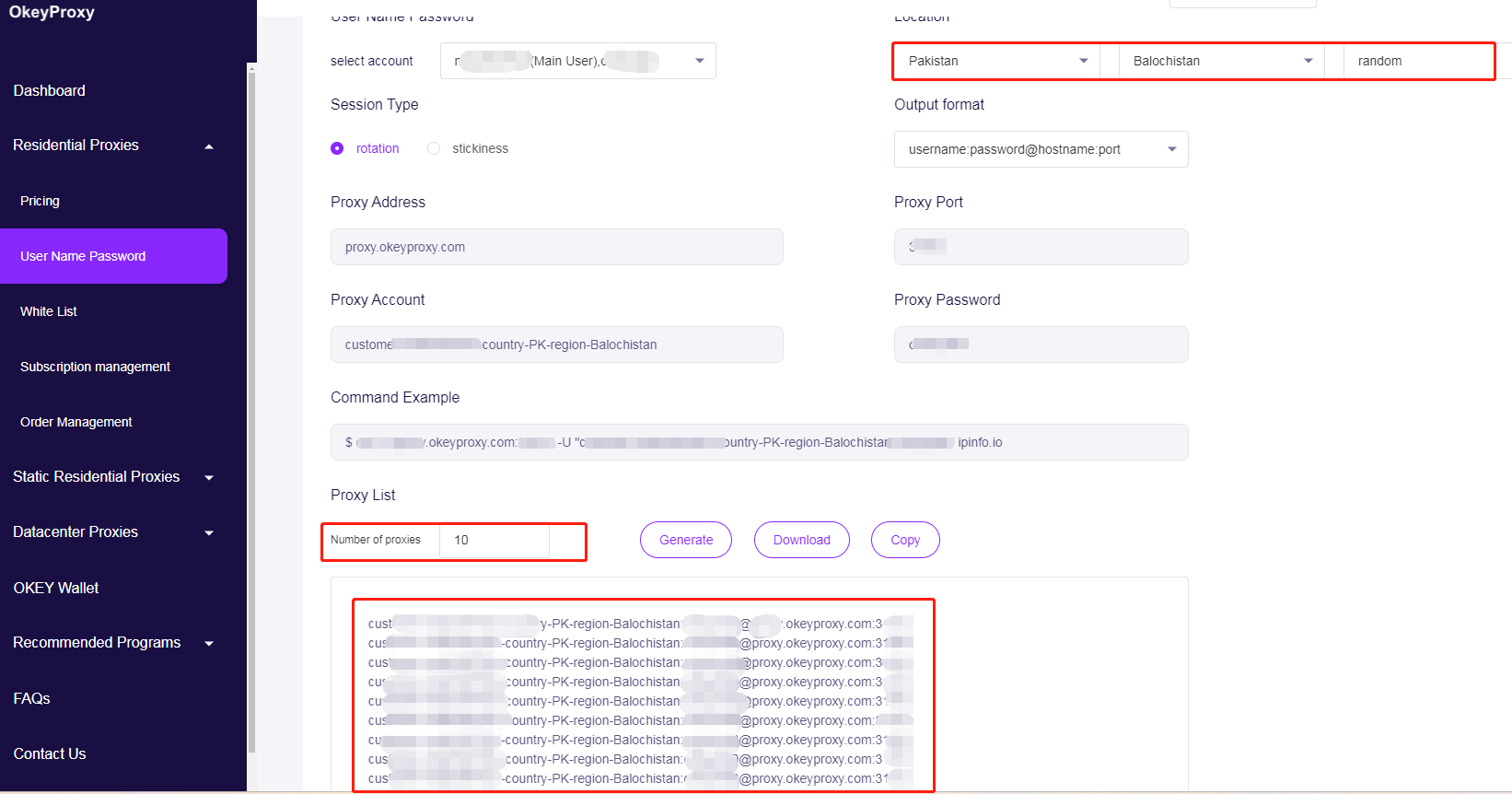
# Proxy-Pool - durch Ihre Proxy-IPs ersetzen
PROXY_POOL = [
"http://username1:[email protected]:1234",
"http://username2:[email protected]:1234",
"http://username3:[email protected]:1234",
"http://username4:[email protected]:1234"
]
# Zufällige Auswahl und Validierung eines Proxys aus dem Pool
def rotate_proxy():
while True:
proxy = random.choice(PROXY_POOL)
if check_proxy(proxy):
return proxy
else:
print(f "Proxy {proxy} ist nicht verfügbar, versuche einen anderen...")
PROXY_POOL.remove(proxy)
raise Exception("Keine gültigen Proxys mehr im Pool.")
# Prüfen Sie, ob ein Proxy funktioniert, indem Sie eine Testanfrage stellen
def check_proxy(proxy):
try:
test_url = "https://httpbin.org/ip"
response = requests.get(test_url, proxies={"http": proxy}, timeout=10)
return response.status_code == 200
außer:
return FalseMit einem Hochwertige Wohnungsvertretungkönnen Sie Web-Crawler oder Scraper in großem Umfang einsetzen, ohne sich Gedanken über Verbote oder Zurückweisungen machen zu müssen.
Wofür werden Data Crawling und Scraping verwendet?
Web Crawling und Web Scraping werden häufig eingesetzt, um wertvolle Erkenntnisse aus den riesigen online verfügbaren Datenmengen zu gewinnen, und sind zu unverzichtbaren Werkzeugen der heutigen Datenwirtschaft geworden.
Einerseits nutzen Unternehmen Web Scraping, um Kundenrezensionen, Forenbeiträge und Konversationen in sozialen Medien für Stimmungsanalysen zu sammeln. Neben der Analyse der Verbraucherstimmung werden durch das Crawling von Daten auch Marktintelligenzplattformen betrieben. Der Markt für alternative Daten, zu dem auch das Web Scraping gehört, wurde im Jahr 2023 auf 4,9 Milliarden USD geschätzt und wird voraussichtlich mit einer Wachstumsrate von jährliche Rate von 28% bis 2032. Tatsächlich werden im Jahr 2024 42,0% der Unternehmensdatenbudgets speziell für die Beschaffung und Verarbeitung von Webdaten bereitgestellt, was die entscheidende Rolle dieser Daten bei der datengestützte Entscheidungsfindung. Und im Einzelhandel nutzen 59% der Einzelhändler Tools zur Überwachung von Wettbewerbspreisen - oft auf der Grundlage von automatisiertem Scraping -, um dynamische Preisstrategien zu optimieren und den Umsatz zu steigern.
Andererseits ist eine der Hauptanwendungen für das Crawling und Scraping von Daten die Unterstützung von KI und maschinelles Lernen Initiativen, wobei 65,0% der Unternehmen Web Scraping als Grundlage für ihre Modelle nutzen. Das Archiv von Common Crawl vom April 2024 beispielsweise sammelte 2,7 Milliarden Webseiten (386 TiB an Inhalten) und diente als Grundlagendatensatz für das Training wichtiger NLP-Modelle. Darüber hinaus haben akademische Forscher und Plattformen wie Semantic Scholar, die über 205 Millionen wissenschaftliche Arbeiten indiziert haben, Webcrawler eingesetzt, um große Mengen an Literatur zu indizieren. Und SEO- und Marketing-Teams nutzen Web-Crawling für Website-Audits, Backlink-Analysen und Wettbewerbsforschung.
Schlussfolgerung
Beim Web-Crawling geht es darum, Seiten zu entdecken und zu besuchen; beim Web-Scraping geht es darum, Daten zu extrahieren. Python macht diese beiden Techniken zugänglich, auch für Nicht-Entwickler.
Durch die Kombination von verantwortungsvollem Crawling, gezieltem Scraping und zuverlässigem Management für Scraping- und Crawling-Proxyskönnen Sie leistungsstarke Datenpipelines aufbauen, die Analysen, maschinelle Lernmodelle und Geschäftseinblicke ermöglichen - ohne Unterbrechung.
Sind Sie bereit, Ihr Web Crawling und Web Scraping zu optimieren? Starten Sie mit einer Erprobung von OkeyProxy und erleben Sie eine nahtlose, groß angelegte Datenerfassung!


Erstklassiger Socks5/Http(s) Proxy-Dienst
- Skalierbare Pläne: Statisch/Rotierende Wohnsitzvollmachten
- Nahtlose Integration: Win/iOS/Android/Linux
- Hohe Sicherheit: Ideal für Antidetect-Browser, Emulatoren, Scraper usw.
- Zuverlässige Leistung: Schnelle Übertragung und geringe Latenzzeit

