1. Что такое Scrapy CrawlSpider?
CrawlSpider является производным классом Scrapy, а принцип работы класса Spider заключается в том, чтобы просматривать только те веб-страницы, которые указаны в списке start_url. Напротив, класс CrawlSpider определяет некоторые правила, чтобы обеспечить удобный механизм для следования по ссылкам - извлечения ссылок из скрапа Amazon веб-страниц и продолжения проползания.
CrawlSpider может подбирать URL-адреса, удовлетворяющие определенным условиям, собирать их в объекты Request и автоматически отправлять в движок, указывая при этом функцию обратного вызова. Другими словами, краулер CrawlSpider может автоматически извлекать соединения в соответствии с заданными правилами.
2. Создание краулера CrawlSpider для скраппинга Amazon
scrapy genspider -t crawl spider_name domain_nameСоздайте команду Scraping Amazon crawler:
Например, чтобы создать краулер Amazon с именем "amazonTop":
scrapy genspider -t crawl amzonTop amazon.comСледующие слова - это весь код:
импорт scrapy
from scrapy.linkextractors import LinkExtractor
из scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider):
name = 'amzonTop'
allowed_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
возврат item
Rules - это кортеж или список, содержащий объекты Rule. Правило состоит из таких параметров, как LinkExtractor, callback и follow.
A. LinkExtractor: Экстрактор ссылок, который подбирает адреса URL с помощью regex, XPath или CSS.
B. обратный вызов: Функция обратного вызова для извлеченных URL-адресов, необязательно.
C. следовать: Указывает, будут ли ответы, соответствующие извлеченным URL-адресам, продолжать обрабатываться правилами. True означает, что будут, а False - что нет.
3. Скраппинг данных о продуктах Amazon
3.1 Создание краулера Scraping Amazon
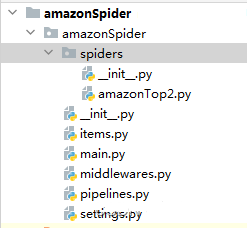
scrapy genspider -t crawl amazonTop2 amazon.com.Структура паучьего кода:
3.2 Извлеките URL-адреса для листания списка товаров и их подробностей.
A. Извлеките все Asin и рейтинг продукта со страницы списка продуктов, т. е. получите Asin и рейтинг из синие коробки на картинке.
B. Извлеките Asin для всех цветов и спецификаций со страницы с подробными сведениями о продукте, т. е. получите Asin из зелёные коробкиСреди них Асин из синих коробок.
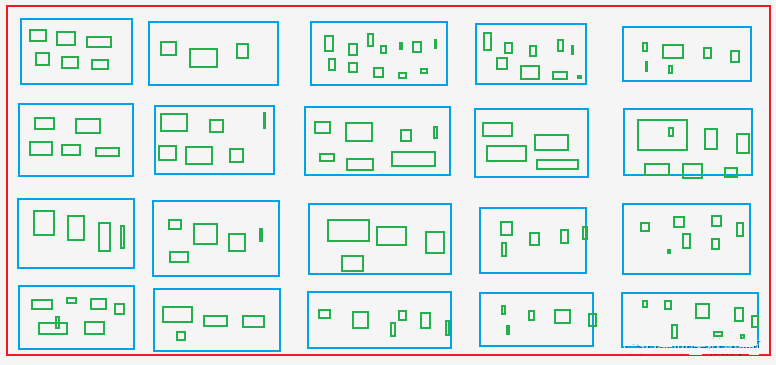
Зеленые коробки: Например, размеры X, M, L, XL и XXL для одежды на сайтах магазинов.
Паук файл: amzonTop2.py
import datetime
импортировать re
импортировать время
из copy import deepcopy
импортировать scrapy
from scrapy.linkextractors import LinkExtractor
из scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
правила = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}
if "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param response:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall(''colorToAsin':(.*?),'refactorEnabled':true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1]
except:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
except:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
для pro_row в pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Ships from"]/div//span//text()').extract()
# 物流方
попробуйте:
доставка = ships_from_list[-1]
except:
доставка = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
if seller == "":
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# else:
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
except:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
except:
цена = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
if brand == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
if pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
материал #
try:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
форма #
shape = pro_detail['Shape'] if "Shape" in key_v else ""
if shape == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
стиль #
# five_points
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num =
стиль #
производитель #
try:
Manufacturer = pro_detail['Manufacturer'] if "Manufacturer" in str(pro_detail) else " "
except:
Manufacturer = ""
item_weight = pro_detail['Item Weight'] if "Weight" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# product_material
try:
product_material = pro_detail['Material']
except:
product_material = ''
# тип_ткани
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list:
try:
star_1 = star_list[0].strip()
except:
star_1 = 0
try:
star_2 = star_list[1].strip()
except:
star_2 = 0
try:
star_3 = star_list[2].strip()
except:
star_3 = 0
try:
star_4 = star_list[3].strip()
кроме:
star_4 = 0
попробовать:
star_5 = star_list[4].strip()
кроме:
star_5 = 0
else:
star_1 = 0
звезда_2 = 0
звезда_3 = 0
звезда_4 = 0
звезда_5 = 0
if "Date First Available" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
else:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# отзывы_num, рейтинги_num
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=seller
item['seller_link']= seller_link
item['brand_link']= brand_link
item['pic_link']=pic_link
item['title']=title
item['brand']=бренд
item['star']=star
item['price']=price
item['color']=color
item['pattern']=pattern
item['material']=material
item['shape']=shape
item['five_points']=five_points
item['size_num']=size_num
item['color_num']=color_num
item['Manufacturer']=Manufacturer
item['item_weight']=item_weight
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=fabric_type
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
выход элемента
При сборе значительного объема данных смените IP и обработайте распознавание капчи.
4. Методы борьбы с посредниками-загрузчиками
4.1 process_request(self, request, spider)
A. Вызывается при прохождении каждого запроса через промежуточное ПО загрузки.
B. Возвращать None: Если значение не возвращается (или явно возвращается None), объект запроса передается загрузчику или другим методам process_request с меньшим весом.
C. Возвращение объекта Response: Больше никаких запросов не выполняется, и ответ возвращается в движок.
D. Возврат объекта запроса: Объект запроса передается планировщику через движок. Другие методы process_request с меньшим весом пропускаются.
4.2 process_response(self, request, response, spider)
A. Вызывается, когда загрузчик завершает HTTP-запрос и передает ответ движку.
B. Возвращаемый ответ: Передается пауку для обработки или методу process_response другого промежуточного ПО загрузки с меньшим весом.
C. Возврат объекта Request: Передается планировщику через движок для дальнейших запросов. Другие методы process_request с меньшим весом пропускаются.
D. Настройте активацию промежуточного ПО и задайте значения весов в файле settings.py. Приоритет отдается меньшим значениям.
middlewares.py
4.3 Настройте IP-адрес прокси-сервера
class ProxyMiddleware(object):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True
вернуть запрос
класс AmazonspiderDownloaderMiddleware:
# Не все методы должны быть определены. Если метод не определен,
# scrapy действует так, как будто промежуточное ПО загрузчика не изменяет
# переданные объекты.
@classmethod
def from_crawler(cls, crawler):
# Этот метод используется Scrapy для создания ваших пауков.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
вернуть s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'куки, вставленные из браузера'
# cookies_str передаются в cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
передать
def spider_opened(self, spider):
spider.logger.info('Паук открыт: %s' % spider.name)
4.5 Получить Скрапбукинг Проверочный код Amazon для разблокировки от Amazon.
def captcha_verfiy(img_name):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if result:
result = result.replace(' ', '')
return result
def download_captcha(captcha_url):
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Загрузка завершена!")
except Exception as e:
print("Ошибка в журнале загрузки!")
class AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
возвращать s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, we just need to make sure you're not a robot" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, we just need to make sure you're not a robot" not in str(response2.text):
return response2
else:
return request
else:
возврат ответа
def process_exception(self, request, exception, spider):
передать
def spider_opened(self, spider):
spider.logger.info('Паук открыт: %s' % spider.name)
Вот и весь код о скрапинге данных Amazon.
Если вы хотите помочь, пожалуйста, сообщите Поддержка OkeyProxy знать.
Рекомендуемые поставщики прокси: Okeyproxy - Топ-5 прокси-провайдеров Socks5 с 150M+ резидентными прокси из 200+ стран. Получите 1 ГБ бесплатной пробной версии прокси-серверов для резидентов прямо сейчас!

