1. Was ist Scrapy CrawlSpider?
CrawlSpider ist eine abgeleitete Klasse von Scrapy, und das Designprinzip der Spider-Klasse ist es, nur die Webseiten in der start_url-Liste zu crawlen. Im Gegensatz dazu definiert die Klasse CrawlSpider einige Regeln, um einen bequemen Mechanismus für das Verfolgen von Links zu bieten - das Extrahieren von Links aus Scraping Amazon Webseiten und setzt das Crawlen fort.
CrawlSpider kann URLs, die bestimmte Bedingungen erfüllen, zu Request-Objekten zusammenstellen und diese automatisch an die Engine senden, wobei eine Callback-Funktion angegeben wird. Mit anderen Worten, der CrawlSpider-Crawler kann automatisch Verbindungen nach vordefinierten Regeln abrufen.
2. Erstellen eines CrawlSpider Crawlers zum Scraping von Amazon
scrapy genspider -t crawl spider_name domain_nameErstellen Sie den Befehl Scraping Amazon crawler:
Zum Beispiel, um einen Amazon-Crawler namens "amazonTop" zu erstellen:
scrapy genspider -t crawl amzonTop amazon.deDie folgenden Wörter sind der gesamte Code:
scrapy importieren
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Regel
class TSpider(CrawlSpider):
name = 'amzonTop '
erlaubte_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['Beschreibung'] = response.xpath('//div[@id="Beschreibung"]').get()
Rückgabe item
Rules ist ein Tupel oder eine Liste, die Rule-Objekte enthält. Eine Regel besteht aus Parametern wie LinkExtractor, Callback und Follow.
A. LinkExtractor: Ein Link-Extraktor, der URL-Adressen mit Regex, XPath oder CSS abgleicht.
B. Rückruf: Eine Callback-Funktion für die extrahierten URL-Adressen, optional.
C. folgen: Gibt an, ob die Antworten, die den extrahierten URL-Adressen entsprechen, weiterhin von den Regeln verarbeitet werden. True bedeutet, dass sie weiterverarbeitet werden, und False bedeutet, dass sie nicht weiterverarbeitet werden.
3. Scraping von Amazon-Produktdaten
3.1 Erstellen eines Scraping-Amazon-Crawlers
scrapy genspider -t crawl amazonTop2 amazon.comDie Struktur von Spider Code:
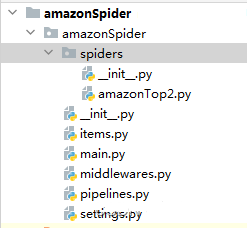
3.2 Extrahieren Sie die URLs für das Blättern in der Produktliste und den Produktdetails.
A. Extrahieren Sie alle Produkt-Asin und -Rang aus der Produktlistenseite, d. h., rufen Sie Asin und Rang aus der Seite blaue Felder auf dem Bild.
B. Extrahieren Sie Asin für alle Farben und Spezifikationen von der Produktdetailseite, d. h., rufen Sie Asin aus der Datei grüne Kästenzu denen auch Asin aus den blauen Boxen gehört.
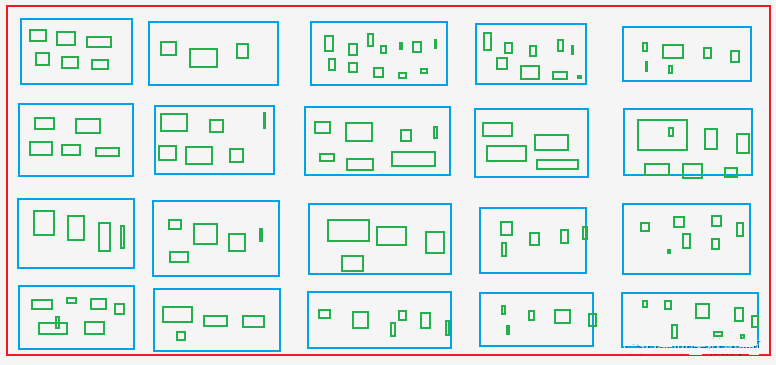
Die grünen Kästchen: Wie die Größen X, M, L, XL und XXL für Kleidung auf Shopping-Websites.
Spider-Datei: amzonTop2.py
import datetime
importiere re
importiere Zeit
von copy importieren deepcopy
importieren scrapy
von scrapy.linkextractors importieren LinkExtractor
from scrapy.spiders import CrawlSpider, Regel
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
rules = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}
if "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(Artikel)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param response:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?), "refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1]
except:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
except:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("übergeordneteASIN:",übergeordneteASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
for pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
schiffe_von_liste = response.xpath(
'//div[@tabular-attribute-name="Schiffe von"]/div//span//text()').extract()
# 物流方
try:
delivery = ships_from_list[-1]
except:
Lieferung = ""
Verkäufer = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
wenn Verkäufer == "":
Verkäufer = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# sonst:
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
except:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
except:
price = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
wenn Marke == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
Marke = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Marke: ", "").replace("Besuchen Sie den", "").replace("Store", '').strip()
color = pro_detail['Farbe'] if "Farbe" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
muster = pro_detail['muster'] if "muster" in key_v else ""
wenn muster == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
#-Material
versuchen:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
# Form
shape = pro_detail['Shape'] if "Shape" in key_v else ""
wenn Form == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
# style
# fünf_Punkte
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num =
# Stil
# Hersteller
try:
Hersteller = pro_detail['Hersteller'] if "Hersteller" in str(pro_detail) else " "
except:
Hersteller = ""
artikel_gewicht = pro_detail['Artikelgewicht'] if "Gewicht" in str(pro_detail) else ''
product_dim = pro_detail['Produktabmessungen'] if "Produktabmessungen" in str(pro_detail) else ''
# produkt_material
try:
produkt_material = pro_detail['Material']
except:
produkt_material = ''
# stoff_type
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list:
try:
star_1 = star_list[0].strip()
except:
star_1 = 0
try:
star_2 = star_list[1].strip()
except:
star_2 = 0
try:
star_3 = star_list[2].strip()
except:
star_3 = 0
try:
star_4 = star_list[3].strip()
except:
star_4 = 0
try:
star_5 = star_list[4].strip()
except:
star_5 = 0
sonst:
star_1 = 0
Stern_2 = 0
stern_3 = 0
stern_4 = 0
stern_5 = 0
if "Datum zuerst verfügbar" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
sonst:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# Bewertungen_num, ratings_num
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['Lieferung']=Lieferung
item['Verkäufer']=Verkäufer
item['seller_link']=verkäufer_link
artikel['marken_link']= marken_link
item['pic_link']=bild_link
item['title']=Titel
item['brand']=brand
item['Stern']=Stern
item['preis']=Preis
item['color']=Farbe
item['Muster']=Muster
item['material']=Material
item['form']=Form
item['fünf_punkte']=fünf_punkte
item['größe_zahl']=Größe_zahl
item['Farbe_Zahl']=Farbe_Zahl
item['Hersteller']=Hersteller
item['artikel_gewicht']=artikel_gewicht
item['produkt_dim']=produkt_dim
item['produkt_material']=produkt_material
item['fabric_type']=Stoffart
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['bewertungen_link']=bewertungen_link
item['Größe']=Größe
item['data_first_available']=data_first_available
Ertrag item
Wenn Sie eine große Menge an Daten sammeln, ändern Sie die IP-Adresse und behandeln Sie die Captcha-Erkennung.
4. Methoden für Downloader-Middlewares
4.1 process_request(self, request, spider)
A. Wird aufgerufen, wenn jede Anfrage die Download-Middleware durchläuft.
B. Return None: Wird kein Wert zurückgegeben (oder wird explizit None zurückgegeben), wird das Request-Objekt an den Downloader oder an andere process_request-Methoden mit geringerem Gewicht übergeben.
C. Rückgabe des Response-Objekts: Es werden keine weiteren Anfragen gestellt, und die Antwort wird an die Engine zurückgegeben.
D. Rückgabe des Request-Objekts: Das Request-Objekt wird über die Engine an den Scheduler übergeben. Andere process_request-Methoden mit geringerem Gewicht werden übersprungen.
4.2 process_response(self, Anfrage, Antwort, Spinne)
A. Wird aufgerufen, wenn der Downloader die HTTP-Anfrage abgeschlossen hat und die Antwort an die Engine weitergibt.
B. Rückgabe der Antwort: Übergabe an den Spider zur Verarbeitung oder an die process_response-Methode einer anderen Download-Middleware mit geringerer Gewichtung.
C. Rückgabe Request-Objekt: Wird über die Engine an den Scheduler für weitere Anfragen weitergeleitet. Andere process_request-Methoden mit geringerem Gewicht werden übersprungen.
D. Konfigurieren Sie die Middleware-Aktivierung und legen Sie die Gewichtungswerte in der Datei settings.py fest. Geringere Gewichte haben Vorrang.
middlewares.py
4.3 Proxy-IP einrichten
class ProxyMiddleware(object):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True
return request
Klasse AmazonspiderDownloaderMiddleware:
# Nicht alle Methoden müssen definiert werden. Wenn eine Methode nicht definiert ist,
verhält sich # scrapy so, als ob die Downloader-Middleware die
# übergebenen Objekte.
@classmethod
def from_crawler(cls, crawler):
# Diese Methode wird von Scrapy verwendet, um Ihre Spider zu erstellen.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
s zurückgeben
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'das vom Browser eingefügte Cookie'
# cookies_str in cookies_dict übertragen
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return Keine
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spinne geöffnet: %s' % spider.name)
4.5 Siehe Kratzen Amazons Verifizierungscode für die Entsperrung von Amazon.
def captcha_verfiy(img_name):
# captcha_verfiy
Leser = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if Ergebnis:
result = result.replace(' ', '')
return result
def download_captcha(captcha_url):
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Download fertig!")
except Exception as e:
print("Fehler im Download-Protokoll!")
class AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, wir müssen nur sicherstellen, dass Sie kein Roboter sind" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, wir müssen nur sicherstellen, dass Sie kein Roboter sind" not in str(response2.text):
return response2
sonst:
Anfrage zurückgeben
sonst:
return antwort
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spinne geöffnet: %s' % spider.name)
Das ist der gesamte Code zum Scraping von Amazon-Daten.
Wenn Sie Hilfe benötigen, lassen Sie es uns bitte wissen OkeyProxy Unterstützung wissen.
Empfohlene Proxy-Lieferanten: Okeyproxy - Top 5 Socks5 Proxy Provider mit 150M+ Residential Proxies aus 200+ Ländern. Holen Sie sich jetzt 1 GB kostenlose Testversion von Residential Proxies!

