1. Scrapy CrawlSpiderとは?
CrawlSpiderはScrapyの派生クラスで、Spiderクラスの設計原則はstart_urlリストにあるウェブページのみをクロールすることです。対照的に、CrawlSpiderクラスは、リンクをたどるための便利なメカニズム、つまりスクレイピングからリンクを抽出するためのいくつかのルールを定義しています。 アマゾン ウェブページをクロールし続ける。
CrawlSpiderは特定の条件を満たすURLをマッチングし、Requestオブジェクトに組み立て、コールバック関数を指定しながら自動的にエンジンに送信することができます。言い換えれば、CrawlSpiderクローラーは事前に定義されたルールに従って自動的に接続を取得することができます。
2. AmazonをスクレイピングするCrawlSpiderクローラーの作成
scrapy genspider -t クロール スパイダー名 ドメイン_nameScrapingアマゾンのクローラーコマンドを作成する:
例えば、"amazonTop "という名前のアマゾンのクローラーを作成する:
scrapy genspider -t crawl amzonTop amazon.com。次の言葉がコード全体である:
インポート scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider):
name = 'amzonTop '
allowed_domains = ['amazon.com'] を許可する。
開始_url = ['https://amazon.com/']
ルール = (
ルール(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)、
)
def parse_item(self, response):
item = {}.
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
アイテムを返す
Rulesは、Ruleオブジェクトを含むタプルまたはリストです。Ruleは、LinkExtractor、callback、followなどのパラメータで構成されます。
A.LinkExtractor: 正規表現、XPath、CSSを使ってURLアドレスをマッチングするリンク抽出ツール。
B. コールバック 抽出されたURLアドレスのコールバック関数。
C.従う: 抽出されたURLアドレスに対応するレスポンスが、引き続きルールによって処理されるかどうかを示します。Trueは処理されることを意味し、Falseは処理されないことを意味します。
3. アマゾン商品データのスクレイピング
3.1 Amazonクローラーの作成
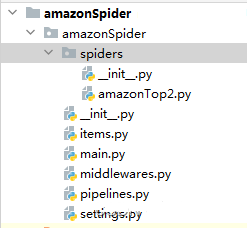
scrapy genspider -t crawl amazonTop2 amazon.com。スパイダーコードの構造:
3.2 商品リストと商品詳細のページング用URLを抽出する。
A.商品一覧ページからすべての商品のAsinとランクを抽出する。 ブルーボックス をイメージしている。
B.商品詳細ページからすべての色と仕様のAsinを抽出する。 グリーンボックスその中には青い箱のアシンも含まれている。
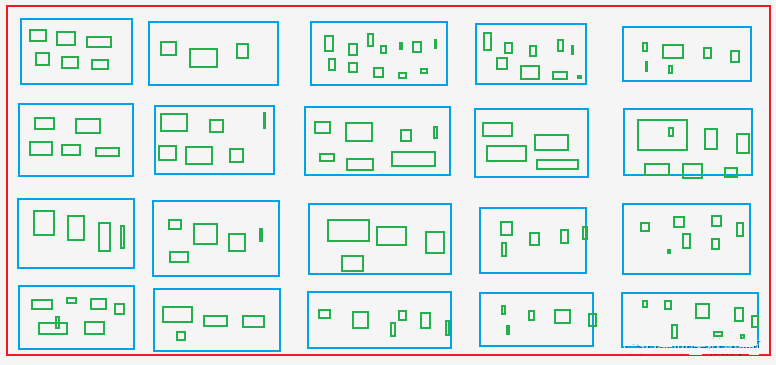
緑色の箱:ショッピングサイトの洋服のサイズX、M、L、XL、XXLのようなもの。
スパイダーファイル: amzonTop2.py
import datetime
インポートre
インポートタイム
from copy import deepcopy
インポート scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com'] ドメインを許可する。
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
開始_url = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
ルール = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True)、
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}。
if "'id'" in str(asinDict):
listProAsin = asinDict['id'].
pro_rank = asinDict['metadataMap']['render.zg.rank'].
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(アイテム)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin、
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param response:
:return:
"""
news_info = response.meta["main_info"].
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?), "refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1].
ただし
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1].
ただし
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
if list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin'].
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']を返します。
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}です。
for pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td/text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute--name="Ships from"]/div//span//text()').extract()
# 物流の方
を試してみてください:
delivery = ships_from_list[-1].
ただし
配送 = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("", "")
if seller == "":
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com"+ seller_link_str
# else:
# seller_link = ''
seller_link = "https://www.amazon.com"+ seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfoo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1/text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
試す
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
ただし
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
ただし
価格 = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['ブランド'] if "ブランド" in key_v else ''
if brand == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
if color == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
if pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
#素材
試す
material = pro_detail['Material'].
ただし
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
#の形状
shape = pro_detail['Shape'] if "Shape" in key_v else ""
if shape == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
#スタイル
# five_points
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num = #スタイル
#スタイル
# メーカー
try:
Manufacturer = pro_detail['Manufacturer'] if "Manufacturer" in str(pro_detail) else " "
を除く:
Manufacturer = ""
item_weight = pro_detail['Item Weight'] if "Weight" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# product_material
try:
product_material = pro_detail['材料']を試してください。
ただし
product_material = ''
#ファブリックタイプ
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
を除く:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list:
try:
star_1 = star_list[0].strip()
ただし
star_1 = 0
try: star_1 = 0:
star_2 = star_list[1].strip()
except: star_2 = 0
star_2 = 0
try: star_2 = 0
star_3 = star_list[2].strip()
except: star_3 = 0
star_3 = 0
try: star_3 = 0:
star_4 = star_list[3].strip()
except: star_4 = 0
star_4 = 0
try: star_4 = 0:
star_5 = star_list[4].strip()
except: star_5 = 0
star_5 = 0
else: star_5 = 0
star_1 = 0
star_2 = 0
star_3 = 0
star_4 = 0
スター_5 = 0
if "Date First Available" in str(pro_detail):
data_first_available = pro_detail['Date First Available'].
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
さもなければ
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# レビュー数, 評価数
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=seller
item['seller_link']=seller_link
item['brand_link']= brand_link
item['pic_link']=pic_link
item['title']=title
item['brand']=brand
item['star']=star
item['price']=price
item['color']=color
item['パターン']=パターン
item['素材']=素材
item['シェイプ']=シェイプ
item['five_points']=five_points
item['size_num']=size_num
item['color_num']=color_num
item['Manufacturer']=Manufacturer
item['item_weight']=item_weight
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=fabric_type
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
項目
相当量のデータを収集する場合は、IPを変更し、キャプチャ認識に対応する。
4. ダウンローダー・ミドルウェアの方法
4.1 process_request(self, request, spider)
A.各リクエストがダウンロードミドルウェアを通過するときに呼び出される。
B.None を返す: 値が返されない場合 (または明示的に None を返す)、 リクエストオブジェクトはダウンローダーや、より重要度の低い他の process_request メソッドに渡される。
C.レスポンスオブジェクトを返す:それ以上のリクエストは行われず、レスポンスがエンジンに返される。
D.リクエスト・オブジェクトを返す:リクエスト・オブジェクトはエンジンを通してスケジューラに渡される。重みの低い他のprocess_requestメソッドはスキップされる。
4.2 process_response(self, request, response, spider)
A.ダウンローダがHTTPリクエストを完了し、レスポンスをエンジンに渡すときに呼び出される。
B.レスポンスを返す:スパイダーに渡され処理されるか、他のダウンロードミドルウェアの process_response メソッドに渡される。
C.Requestオブジェクトを返す:更なるリクエストのためにエンジンを通してスケジューラに渡される。他のprocess_requestメソッドで重みが低いものはスキップされる。
D.settings.pyでミドルウェアのアクティベーションを設定し、ウェイト値を設定する。重みが小さい方が優先されます。
middlewares.py
4.3 プロキシIPの設定
クラス ProxyMiddleware(object):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status != '200':
request.dont_filter = True
リクエストを返す
クラス AmazonspiderDownloaderMiddleware:
# すべてのメソッドを定義する必要はありません。メソッドが定義されていない場合
# scrapyは、ダウンローダミドルウェアがオブジェクトを変更しないかのように動作します。
#渡されたオブジェクトを変更しないものとして動作します。
クラスメソッド
def from_crawler(cls, crawler):
# このメソッドは、Scrapyがスパイダーを作成するために使用します。
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'ブラウザから貼り付けられたクッキー'
# cookies_strをcookies_dictに転送する
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}.
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
リターン None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
パス
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
4.5 取得 スクレイピング Amazonからのブロックを解除するための認証コード。
def captcha_verfiy(img_name):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0].
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if result:
result = result.replace(' ', '')
結果を返す
def download_captcha(captcha_url):
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Download done!")
except Exception as e:
print("Download log error!")
クラス AmazonspiderVerifyMiddleware:
クラスメソッド
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
ヘッダー = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0 Safari/537.36"
}
セッション = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "申し訳ありませんが、ロボットでないことを確認する必要があります" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "申し訳ありませんが、我々はあなたがロボットではないことを確認する必要があります" not in str(response2.text):
return response2
else:
リクエストを返す
を返します:
レスポンスを返す
def process_exception(self, request, exception, spider):
パス
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
以上、アマゾンのデータのスクレイピングに関するコードでした。
何かお手伝いできることがあれば、ご連絡ください。 OkeyProxy サポート 知っている。
推奨される代理サプライヤー オッケープロキシー - 200以上の国から150M以上の居住プロキシを持つトップ5のSocks5プロキシプロバイダ。 レジデンシャル・プロキシーの1GB無料トライアルを今すぐご利用ください。!

