
























Web Crawling vs Web Scraping: A Beginner’s Guide
Imagine the internet as a massive library. Web crawling is like sending out librarians to explore every hallway, noting down every book’s title and location. Web scraping is like asking a specific librarian to pull out select chapters from certain books you need. Both are essential—but they work differently and serve different goals.
In this guide, we’ll explain each concept in plain English, show you beginner-friendly examples, and help you decide which approach fits your project.
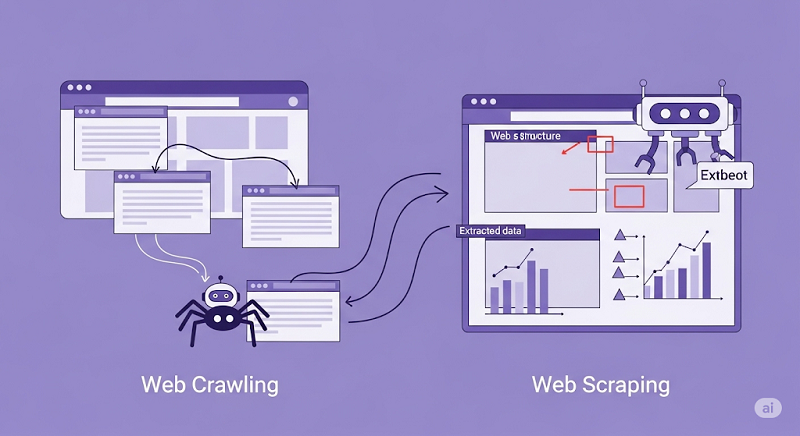
What Is Web Crawling?
Definition
Automated exploration of websites to find and index pages.
How It Works
- Start from one webpage (the “seed”).
- Read all the links on that page.
- Visit each link, repeat.
Analogy
A librarian walking through every library aisle, noting every book on their list.
Use Cases for Beginners
Building a site map to visualize your own website’s pages.
Checking for broken links or missing pages on a blog.
What Is Web Scraping?
Definition
Extracting specific pieces of information from web pages.
How It Works
- Identify the target pages (e.g., product listings).
- Find the HTML elements that hold your data (like price tags).
- Pull out that data and save it (e.g., into a spreadsheet).
Analogy
Telling a librarian, “Please grab me Chapter 3 and the table of contents from these three books.”
Use Cases for Beginners
Tracking prices on an e-commerce site.
Collecting names and email addresses from a public directory.
Key Differences at a Glance
| Feature | Web Crawling | Web Scraping |
| Main Goal | Discover as many pages as possible | Extract specific data points |
| Output | List of URLs, basic page info | Structured data (CSV, JSON, etc.) |
| Scope | Entire site or web segment | Selected pages or fields |
| Beginner Skill Level | Easy to start with ready tools | Requires some HTML/selector knowledge |
Beginner-Friendly Examples
Crawling with Screaming Frog (no code)
1. Download and open Screaming Frog SEO Spider.
2. Enter your website’s URL.
3. Click “Start” to crawl.
4. Review the “Internal” tab for all discovered URLs and any broken links.
Scraping with a Browser Extension (no code)
1. Install a simple scraper extension like “Web Scraper” for Chrome.
2. Point-and-click on the data you want (e.g., prices).
3. Export the data as CSV.
These tools let you practice without writing any code—and they introduce key concepts like site structure and HTML selectors.
You may also be interested:
3. Scrape SERP for SEO Insights
When to Use Which?
Pick Crawling If You Need
An overall picture of all pages on your website.
To audit links, images, or meta tags site-wide.
Pick Scraping If You Need
Specific details like product names, prices, or contact info.
Data you can analyze in Excel or load into a database.
Combine Both
Crawl to discover all relevant pages.
Scrape only those pages for the exact data you want.
Easy Best Practices for Beginners
Respect Robots.txt: Most sites publish a robots.txt file—check it to see which pages you’re allowed to crawl or scrape.
Throttle Your Requests: Don’t overwhelm a site—wait a second or two between each page load.
Use Readable Output: Start by saving your data to a simple CSV file so you can inspect it in Excel.
Keep Learning HTML Basics: A little knowledge of tags like <div>, <span>, and CSS selectors goes a long way.
Start Small: Practice on your own blog or a test site before scaling up.
Conclusion
Web crawling and web scraping are two sides of the same coin: one helps you map the web, the other helps you harvest the data you need. As a beginner, start with no-code tools to get comfortable. Then, gradually explore simple code libraries when you're ready for more control.
By understanding their differences—and when to use each—you’ll build efficient workflows that save time and deliver reliable data.
