1. O que é o Scrapy CrawlSpider?
A classe CrawlSpider é uma classe derivada do Scrapy, e o princípio de conceção da classe Spider é o de rastrear apenas as páginas web na lista start_url. Em contraste, a classe CrawlSpider define algumas regras para fornecer um mecanismo conveniente para seguir ligações - extrair ligações a partir da recolha de dados Amazon páginas web e continuar o rastreio.
O CrawlSpider pode fazer corresponder URLs que satisfazem determinadas condições, reuni-los em objectos Request e enviá-los automaticamente para o motor, especificando uma função de retorno de chamada. Por outras palavras, o crawler CrawlSpider pode obter automaticamente ligações de acordo com regras predefinidas.
2. Criando um CrawlSpider Crawler para raspar a Amazon
scrapy genspider -t crawl spider_name domain_nameCriar o comando Scraping Amazon crawler:
Por exemplo, para criar um rastreador da Amazon chamado "amazonTop":
scrapy genspider -t crawl amzonTop amazon.comAs palavras seguintes constituem o código completo:
importar scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
classe TSpider(CrawlSpider):
name = 'amzonTop '
allowed_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
regras = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
devolver item
Rules é uma tupla ou lista que contém objectos Rule. Uma Rule consiste em parâmetros como LinkExtractor, callback e follow.
A. LinkExtractor: Um extrator de ligações que corresponde a endereços URL utilizando regex, XPath ou CSS.
B. retorno de chamada: Uma função de retorno de chamada para os endereços URL extraídos, opcional.
C. seguir: Indica se as respostas correspondentes aos endereços URL extraídos continuarão a ser processadas pelas regras. Verdadeiro significa que continuarão, e Falso significa que não continuarão.
3. Recolha de dados de produtos da Amazon
3.1 Criar um rastreador Scraping Amazon
scrapy genspider -t crawl amazonTop2 amazon.comA estrutura do Código Spider:
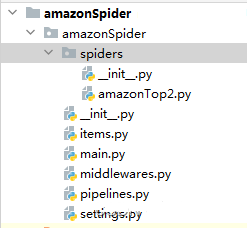
3.2 Extrair os URLs para paginar a lista de produtos e os detalhes do produto.
A. Extrair o Asin e a classificação de todos os produtos da página da lista de produtos, ou seja, obter o Asin e a classificação da página caixas azuis na imagem.
B. Extrair o Asin para todas as cores e especificações da página de detalhes do produto, ou seja, obter o Asin da caixas verdesque incluem Asin das caixas azuis.
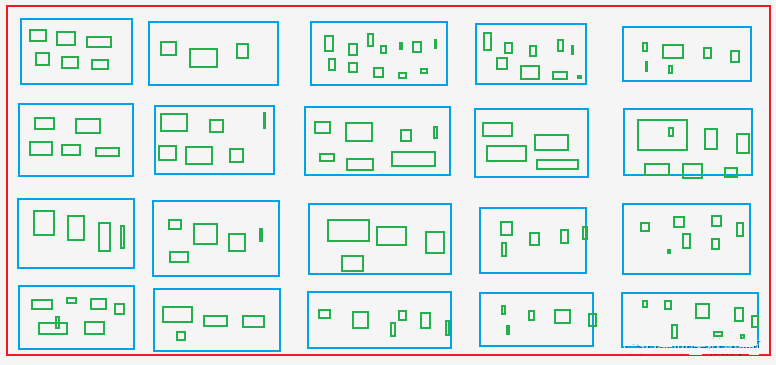
As caixas verdes: Como os tamanhos X, M, L, XL e XXL para roupas em sites de compras.
Ficheiro aranha: amzonTop2.py
importar datetime
importar re
import time
from copy import deepcopy
importar scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
classe Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
regras = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
se asin_list_str:
asin_list = eval(asin_list_str)
for asinDict in asin_list:
item = {}
se "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param response:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?), "refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1]
exceto:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
exceto:
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
se list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
for asin_min_key, asin_min_value in list_ASIN_all_dict.items():
if asin_min_value:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# with open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
para pro_linha em pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
lista_de_navios = response.xpath(
'//div[@tabular-attribute-name="Navios de"]/div//span//text()').extract()
# 物流方
tentar:
delivery = ships_from_list[-1]
except:
entrega = ""
vendedor = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
se vendedor == "":
vendedor = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# else:
# seller_link = ''
link_do_vendedor = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
título = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
tentar:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
exceto:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
exceto:
preço = ''
tamanho = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
se marca == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif marca == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Cor'] if "Cor" in key_v else ""
se cor == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="nome_da_cor_variação"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
se pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
Material #
try:
material = pro_detail['Material']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
Forma do #
shape = pro_detail['Shape'] if "Shape" in key_v else ""
se forma == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
Estilo #
# cinco_pontos
cinco_pontos =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="nome_do_tamanho_da_variação"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num =
Estilo do #
# fabricante
try:
Fabricante = pro_detail['Fabricante'] if "Fabricante" in str(pro_detail) else " "
exceto:
Fabricante = ""
peso_do_item = pro_detail['Peso do item'] if "Peso" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# material_do_produto
try:
material_do_produto = pro_detail['Material']
except:
material_do_produto = ''
# tipo_de_tecido
try:
tipo_de_tecido = pro_detail['Tipo de tecido'] if "Tipo de tecido" in str(pro_detail) else " "
exceto:
tipo_de_tecido = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
se lista_estrela:
try:
star_1 = star_list[0].strip()
exceto:
estrela_1 = 0
tenta:
estrela_2 = lista_de_estrelas[1].tira()
exceto:
estrela_2 = 0
tenta:
estrela_3 = lista_de_estrelas[2].tira()
exceto:
estrela_3 = 0
tenta:
estrela_4 = lista_de_estrelas[3].tira()
exceto:
estrela_4 = 0
tenta:
estrela_5 = lista_de_estrelas[4].tira()
exceto:
estrela_5 = 0
senão:
estrela_1 = 0
estrela_2 = 0
estrela_3 = 0
estrela_4 = 0
estrela_5 = 0
if "Data da primeira disponibilidade" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
senão:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# número_de_revistas, número_de_avaliações
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=seller
item['seller_link']= seller_link
item['brand_link']= brand_link
item['pic_link']=pic_link
item['title']=title
item['marca']=marca
item['star']=estrela
item['price']=preço
item['cor']=cor
item['pattern']=padrão
item['material']=material
item['shape']=forma
item['five_points']=five_points
item['size_num']=size_num
item['color_num']=color_num
item['Fabricante']=Fabricante
item['peso_do_item']=peso_do_item
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=fabric_type
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['link_reviews']=link_reviews
item['size']=size
item['data_first_available']=data_first_available
produzir item
Quando recolher uma quantidade substancial de dados, altere o IP e trate do reconhecimento de captcha.
4. Métodos para Middlewares Downloader
4.1 process_request(self, request, spider)
A. Chamado quando cada pedido passa pelo middleware de descarregamento.
B. Devolver Nenhum: Se não for devolvido qualquer valor (ou devolver explicitamente Nenhum), o objeto pedido é passado para o descarregador ou para outros métodos process_request com menor peso.
C. Devolver objeto de resposta: Não são efectuados mais pedidos e a resposta é devolvida ao motor.
D. Devolver o objeto de pedido: O objeto pedido é passado para o programador através do motor. Outros métodos process_request com menor peso são ignorados.
4.2 process_response(self, request, response, spider)
A. Chamado quando o descarregador conclui o pedido HTTP e passa a resposta ao motor.
B. Resposta de retorno: Transmitida ao spider para processamento ou ao método process_response de outro middleware de descarregamento com menor peso.
C. Devolver o objeto Pedido: Transmitido ao programador através do motor para outros pedidos. Outros métodos process_request com menor peso são ignorados.
D. Configure a ativação do middleware e defina os valores de peso em settings.py. Os pesos mais baixos são priorizados.
middlewares.py
4.3 Configurar o IP do proxy
classe ProxyMiddleware(object):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status ! = '200':
request.dont_filter = True
retornar pedido
class AmazonspiderDownloaderMiddleware:
# Nem todos os métodos precisam ser definidos. Se um método não for definido,
# scrapy age como se o middleware downloader não modificasse os
# objectos passados.
Método de classe
def from_crawler(cls, crawler):
# Este método é usado pelo Scrapy para criar seus spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
retornar s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'o cookie colado do browser'
# transferência de cookies_str para cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
4.5 Obter Raspagem Código de verificação da Amazon para desbloquear a partir da Amazon.
def captcha_verfiy(img_name):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
resultado = reader.readtext(nome_da_imagem, detalhe=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
se resultado:
resultado = resultado.replace(' ', '')
devolver resultado
def download_captcha(captcha_url):
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try:
with open(r'./captcha.png', 'wb') as logFile:
for chunk in response:
logFile.write(chunk)
logFile.close()
print("Download feito!")
exceto Exception as e:
print("Erro no registo da transferência!")
classe AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
if 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/109.0.0.0 Safari/537.36"
}
sessão = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@nome='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@nome='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, we just need to make sure you're not a robot" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, we just need to make sure you're not a robot" not in str(response2.text):
return response2
senão:
return request
senão:
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
Este é todo o código sobre a recolha de dados da Amazon.
Se alguém puder ajudar, por favor contacte Suporte OkeyProxy saber.
Fornecedores de proxy recomendados: Okeyproxy - Top 5 Socks5 Proxy Provider com 150M+ Residential Proxies de 200+ países. Obtenha agora uma avaliação gratuita de 1GB de Residential Proxies!

