1. Qu'est-ce que Scrapy CrawlSpider ?
CrawlSpider est une classe dérivée de Scrapy, et le principe de conception de la classe Spider est de n'explorer que les pages web de la liste start_url. En revanche, la classe CrawlSpider définit certaines règles afin de fournir un mécanisme pratique pour suivre les liens - extraire les liens du scraping Amazon pages web et de poursuivre l'exploration.
CrawlSpider peut faire correspondre les URL qui remplissent certaines conditions, les assembler en objets Request et les envoyer automatiquement au moteur tout en spécifiant une fonction de rappel. En d'autres termes, le crawler CrawlSpider peut récupérer automatiquement des connexions selon des règles prédéfinies.
2. Création d'un CrawlSpider pour scraper Amazon
scrapy genspider -t crawl spider_name domain_nameCréer la commande Scraping Amazon crawler :
Par exemple, pour créer un crawler Amazon nommé "amazonTop" :
scrapy genspider -t crawl amzonTop amazon.comLes mots suivants constituent l'intégralité du code :
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TSpider(CrawlSpider) :
name = 'amzonTop '
allowed_domains = ['amazon.com']
start_urls = ['https://amazon.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response) :
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item
Rules est un tuple ou une liste contenant des objets Rule. Une règle se compose de paramètres tels que LinkExtractor, callback et follow.
A. LinkExtractor : Un extracteur de liens qui fait correspondre les adresses URL à l'aide d'une expression rationnelle, de XPath ou de CSS.
B. callback : Une fonction de rappel pour les adresses URL extraites, facultative.
C. suivre : Indique si les réponses correspondant aux adresses URL extraites continueront à être traitées par les règles. True signifie qu'elles le seront, False signifie qu'elles ne le seront pas.
3. Récupérer les données des produits Amazon
3.1 Créer un crawler Amazon Scraping
scrapy genspider -t crawl amazonTop2 amazon.comLa structure du code Spider:
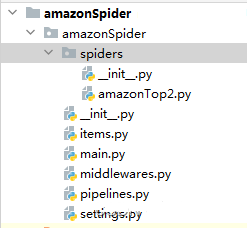
3.2 Extraire les URL pour la pagination de la liste des produits et des détails des produits.
A. Extraire l'Asin et le rang de tous les produits de la page de liste des produits, c'est-à-dire extraire l'Asin et le rang de la page de liste des produits. boîtes bleues dans l'image.
B. Extraire l'Asin pour toutes les couleurs et spécifications de la page de détails du produit, c'est-à-dire extraire l'Asin de la page de détails du produit, c'est-à-dire extraire l'Asin de la page de détails du produit. boîtes vertesqui incluent Asin dans les boîtes bleues.
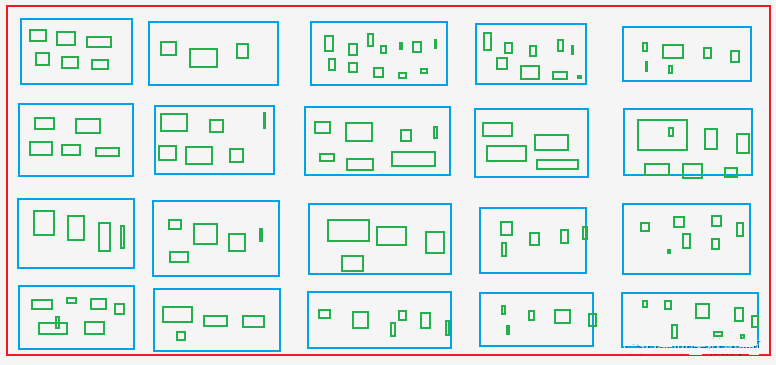
Les boîtes vertes : Comme les tailles X, M, L, XL et XXL pour les vêtements sur les sites d'achat.
Fichier araignée : amzonTop2.py
importer datetime
import re
import time
from copy import deepcopy
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Amazontop2Spider(CrawlSpider) :
nom = 'amazonTop2'
allowed_domains = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
rules = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response) :
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
if asin_list_str :
asin_list = eval(asin_list_str)
for asinDict in asin_list :
item = {}
if "'id'" in str(asinDict) :
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rang'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info" : deepcopy(item)})
def parse_list_asin(self, response) :
"""
:param response :
:return :
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin" :(.* ?), "refactorEnabled":true,', str(response.text))
try :
try :
parentASIN = re.findall(r', "parentAsin" :"(.* ?)",', str(response.text))[-1]
except :
parentASIN = re.findall(r'&parentAsin=(.* ?)&', str(response.text))[-1]
sauf :
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN :",parentASIN)
if list_ASIN_all_findall :
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
pour asin_min_key, asin_min_value dans list_ASIN_all_dict.items() :
if asin_min_value :
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info" : deepcopy(news_info)})
def parse_detail_info(self, response) :
"""
:param response :
:return :
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# avec open('amazon_h.html', 'w') as f :
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
for pro_row in pro_details :
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Ships from"]/div//span//text()').extract()
# 物流方
try :
livraison = ships_from_list[-1]
except :
livraison = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
si vendeur == "" :
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/text()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract()))
# if seller_link_str :
# seller_link = "https://www.amazon.com" + seller_link_str
# else :
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
try :
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
sauf :
try :
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
sauf :
price = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
si marque == '' :
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "" :
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Marque : ", "").replace("Visitez le", "").replace("Magasin", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
si couleur == "" :
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '' :
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
si motif == "" :
motif = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
Matériau #
essayer :
material = pro_detail['Material']
except :
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
Forme #
shape = pro_detail['Shape'] if "Shape" in key_v else ""
si forme == "" :
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
# style
# cinq_points
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="variation_size_name"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variant_num =
# style
# fabricant
essayer :
Fabricant = pro_detail['Fabricant'] if "Fabricant" in str(pro_detail) else " "
sauf :
Fabricant = ""
item_weight = pro_detail['Poids de l'article'] if "Poids" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# produit_matériau
essayer :
produit_matériel = pro_detail['Matériau']
except :
product_material = ''
# type_de_tissu
essayer :
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except :
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
if star_list :
try :
star_1 = star_list[0].strip()
except :
star_1 = 0
try :
star_2 = star_list[1].strip()
sauf : star_2 = star_list[1].strip()
star_2 = 0
essayer :
star_3 = star_list[2].strip()
sauf : star_3 = star_list[2].strip()
star_3 = 0
essayer :
star_4 = star_list[3].strip()
sauf : star_4 = 0
star_4 = 0
essayer :
star_5 = star_list[4].strip()
sauf : star_5 = star_list[4].strip()
star_5 = 0
else :
étoile_1 = 0
étoile_2 = 0
étoile_3 = 0
étoile_4 = 0
étoile_5 = 0
if "Date First Available" in str(pro_detail) :
data_first_available = pro_detail['Date First Available']
if data_first_available :
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
sinon :
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# reviews_num, ratings_num
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
item['delivery']=delivery
item['seller']=vendeur
item['seller_link']= seller_link
item['brand_link']= brand_link
item['pic_link'] =pic_link
item['title']=titre
item['brand']=marque
item['star']=star
item['price']=prix
item['color']=color
item['pattern']=pattern
item['material']=material
item['shape']=shape
item['cinq_points']=cinq_points
item['size_num']=size_num
item['color_num']=color_num
item['Fabricant']=Fabricant
item['item_weight']=poids_de_l'item
item['product_dim']=product_dim
item['product_material']=product_material
item['fabric_type']=type_de_tissu
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
yield item
Lors de la collecte d'une quantité importante de données, changez d'adresse IP et gérez la reconnaissance captcha.
4. Méthodes pour les logiciels intermédiaires de téléchargement
4.1 process_request(self, request, spider)
A. Appelé lorsque chaque demande passe par l'intergiciel de téléchargement.
B. Return None : Si aucune valeur n'est renvoyée (ou si l'on renvoie explicitement None), l'objet de la demande est transmis au téléchargeur ou à d'autres méthodes process_request de moindre importance.
C. Renvoi de l'objet Response : Aucune autre demande n'est effectuée et la réponse est renvoyée au moteur.
D. Renvoi de l'objet Request : L'objet de la demande est transmis à l'ordonnanceur par l'intermédiaire du moteur. Les autres méthodes process_request de moindre importance sont ignorées.
4.2 process_response(self, request, response, spider)
A. Appelé lorsque le téléchargeur termine la requête HTTP et transmet la réponse au moteur.
B. Réponse en retour : Transmise à l'araignée pour traitement ou à la méthode process_response d'un autre logiciel intermédiaire de téléchargement avec un poids inférieur.
C. Renvoi de l'objet "Request" : Transmis au planificateur par l'intermédiaire du moteur pour d'autres demandes. Les autres méthodes process_request de moindre importance sont ignorées.
D. Configurer l'activation de l'intergiciel et définir les valeurs de poids dans settings.py. Les poids les plus faibles sont prioritaires.
middlewares.py
4.3 Configurer l'IP du proxy
classe ProxyMiddleware(objet) :
def process_request(self,request, spider) :
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider) :
if response.status != '200' :
request.dont_filter = True
Retourner la requête
classe AmazonspiderDownloaderMiddleware :
# Il n'est pas nécessaire de définir toutes les méthodes. Si une méthode n'est pas définie,
# scrapy agit comme si l'intergiciel de téléchargement ne modifiait pas les objets transmis.
# objets passés.
@classmethod
def from_crawler(cls, crawler) :
# Cette méthode est utilisée par Scrapy pour créer vos spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
retour s
def process_request(self, request, spider) :
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'le cookie collé depuis le navigateur'
# cookies_str transfert vers cookies_dict
cookies_dict = {i[:i.find('=')] : i[i.find('=') + 1 :] for i in cookies_str.split(' ; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
return None
def process_response(self, request, response, spider) :
return response
def process_exception(self, request, exception, spider) :
passe
def spider_opened(self, spider) :
spider.logger.info('Araignée ouverte : %s' % spider.name)
4.5 Obtenir Grattage Code de vérification d'Amazon pour le déblocage à partir d'Amazon.
def captcha_verfiy(img_name) :
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
result = reader.readtext(img_name, detail=0)[0]
# result = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
if result :
result = result.replace(' ', '')
return result
def download_captcha(captcha_url) :
# dowload-captcha
response = requests.get(captcha_url, stream=True)
try :
with open(r'./captcha.png', 'wb') as logFile :
for chunk in response :
logFile.write(chunk)
logFile.close()
print("Téléchargement terminé !")
except Exception as e :
print("Erreur du journal de téléchargement !")
classe AmazonSpiderVerifyMiddleware :
@classmethod
def from_crawler(cls, crawler) :
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider) :
return None
def process_response(self, request, response, spider) :
# print(response.url)
if 'Captcha' in response.text :
headers = {
"user-agent" : "Mozilla/5.0 (Windows NT 10.0 ; Win64 ; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@name='amzn']/@value"))
amz_tr = "".join(response1.xpath("//input[@name='amzn-r']/@value"))
download_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Sorry, we just need to make sure you're not a robot" not in str(resp.text) :
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Sorry, we just need to make sure you're not a robot" not in str(response2.text) :
return response2
else :
retour de la demande
else :
retour de la réponse
def process_exception(self, request, exception, spider) :
pass
def spider_opened(self, spider) :
spider.logger.info('Araignée ouverte : %s' % spider.name)
C'est tout le code concernant la récupération des données d'Amazon.
Si vous avez besoin d'aide, n'hésitez pas à nous contacter. Support OkeyProxy savoir.
Fournisseurs de procuration recommandés : Okeyproxy - Top 5 Socks5 Proxy Provider avec 150M+ Residential Proxies from 200+ Countries. Obtenez 1GB d'essai gratuit de Residential Proxies maintenant!

