Introducción
En la era digital, a menudo se dice que los datos son el nuevo oro. Empresas, investigadores y particulares confían en los datos para tomar decisiones informadas, obtener información y seguir siendo competitivos. El web scraping, el proceso de extracción de datos de sitios web, se ha convertido en una herramienta indispensable en este proceso de búsqueda de información. Sin embargo, la búsqueda web no está exenta de desafíos, el más destacado de los cuales es la necesidad de un agente. En esta completa guía, exploraremos cómo puede aprovechar los proxies de scraping para mejorar sus esfuerzos de Data Scraping y proporcionarle una ventaja competitiva.
Más información sobre Proxy Scraping
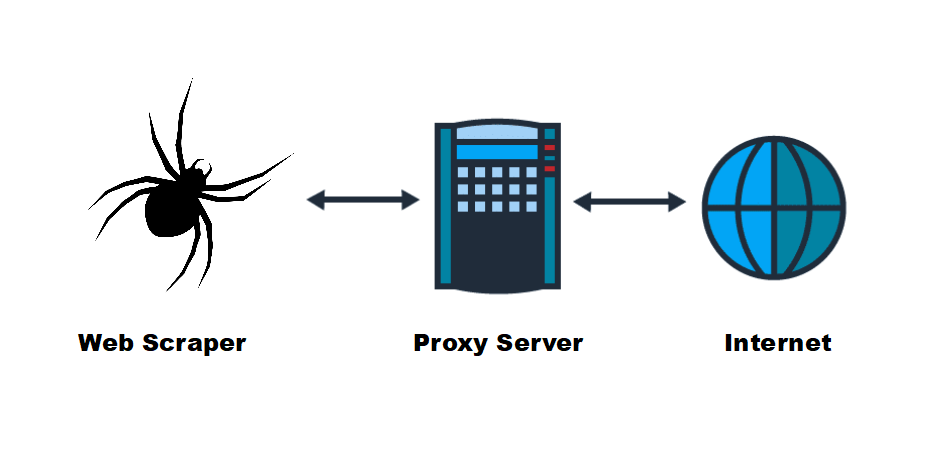
Antes de sumergirnos en el uso de proxies para el web scraping, aclaremos primero qué es un proxy y qué hace. Un proxy actúa como intermediario entre tu ordenador y el servidor web al que intentas acceder. Cuando utilizas un proxy para solicitar datos de un sitio web, el servidor proxy realiza la solicitud en tu nombre, enmascarando tu dirección IP en el proceso. Esto es crucial para las búsquedas en Internet, ya que le permite permanecer en el anonimato y evitar ser detectado.
¿Por qué utilizar un proxy para el web scraping?
A. Superar el bloqueo y las restricciones de IP
Muchos sitios web emplean medidas anti-scraping para impedir la recogida automatizada de datos. Pueden bloquear las direcciones IP que realizan demasiadas solicitudes en un corto periodo de tiempo, o restringir el acceso a usuarios de regiones específicas. Al utilizar un servidor proxy, usted rota a través de un conjunto de direcciones IP, lo que dificulta que los sitios web detecten y bloqueen su actividad de búsqueda.
B. Garantizar el anonimato y la privacidad
El raspado de múltiples páginas web o sitios web sin un proxy puede dar lugar a la prohibición de su dirección IP. Esto no sólo interrumpe la recopilación de datos, sino que también compromete su privacidad. Los proxies proporcionan un anonimato adicional, garantizando que tu dirección IP real quede oculta al raspar datos de la web.
Tipo de proxies de raspado
Hay varios tipos de servidores proxy entre los que elegir, cada uno con sus propias ventajas y usos:
A. Representación residencial
Un proxy residencial es una dirección IP asignada a una zona residencial real. Como parecen conexiones de usuario legítimas, los sitios web confían mucho en ellos. Los proxies residenciales son ideales cuando necesitas acceder a datos de un sitio web con estrictas medidas de seguridad.
B. Proxy de centro de datos
Un proxy de centro de datos es una dirección IP alojada en un centro de datos. Los proxies de centros de datos son más rápidos y rentables que los proxies residenciales, pero puede que los sitios web no confíen tanto en ellos. El agente de centro de datos es adecuado para tareas que requieren velocidad y eficacia.
C.Servidor proxy SOCKS
Los servidores proxy SOCKS son versátiles y pueden gestionar todo tipo de tráfico de Internet, lo que los convierte en una opción popular para las búsquedas web. Combinan ventajas de seguridad y rendimiento, lo que los convierte en una opción completa para la recopilación de datos.
D. Proxy rotatorio
Los proxies rotatorios cambian constantemente de dirección IP, lo que dificulta que los sitios web identifiquen y bloqueen la actividad de búsqueda. Son una opción popular para operaciones de búsqueda a gran escala.
Elegir el proveedor de proxies de scraping adecuado
Elegir el proveedor de proxy adecuado es fundamental para el éxito de sus esfuerzos de búsqueda en Internet. A la hora de elegir un proveedor, hay que tener en cuenta factores como la fiabilidad, la velocidad, la cobertura geográfica y el precio. Algunos de los proveedores de proxy más utilizados son Luminati, Oxylabs y Smartproxy.
Instalar y configurar un Proxy de Scraping
Configurar un proxy para el scraping web requiere ajustar la configuración de la herramienta de scraping para que las peticiones se dirijan a través del servidor proxy. Además, puede ser necesario gestionar la autenticación y aplicar una estrategia de rotación de proxy para evitar la detección.
Prácticas recomendadas para el uso de Scraping Proxy
El Web Scraping no es una panacea, y utilizar un servidor proxy de forma efectiva requiere adherirse a las mejores prácticas. Considera la posibilidad de limitar la velocidad y la estrangulación, la supervisión y el registro, y una gestión de errores sólida para garantizar operaciones de búsqueda sin problemas.
Solucionar los problemas más comunes del proxy
A pesar de sus mejores esfuerzos, puede encontrarse con problemas como el bloqueo de IP y CAPTCHAs al raspar la web. Aprender a solucionar estos problemas comunes relacionados con los agentes es fundamental para mantener un proceso de recopilación de datos sin problemas.
Estudio de caso
Los ejemplos reales de scraping web realizado con éxito utilizando proxies pueden proporcionarle valiosas ideas sobre cómo aplicar los proxies a diversas situaciones. Estos casos prácticos ilustran las ventajas prácticas de incorporar agentes a su flujo de trabajo de recopilación de datos.
Conclusión
En resumen, la búsqueda web es una poderosa herramienta de recopilación de datos, y los agentes son la clave para liberar todo su potencial. Mediante el uso de un proxy, puede superar el bloqueo de IP, garantizar el anonimato y recopilar datos de forma más eficaz. Con el proveedor de agencias adecuado y las mejores prácticas, puede mejorar sus esfuerzos de recopilación de datos y obtener una ventaja competitiva en el mundo actual impulsado por los datos.