
No domínio da recolha de dados da Web, os proxies desempenham um papel crucial para garantir uma recolha de dados sem problemas e sem interrupções. Ao extrair grandes quantidades de dados de sites, é comum encontrar bloqueios de IP ou limites de taxa. É aqui que os proxies proxy scraper são úteis - ajudam a contornar estas restrições e tornam a recolha de dados mais eficiente e anónima.
Este blogue explicará o que são proxies scraper proxy, porque são essenciais para o scraping e como utilizar os proxies certos para as suas necessidades.
O que são scrapers proxy?
Os proxy scrapers são proxies especializados utilizados durante a recolha de dados da Web. Funcionam como intermediários entre a sua ferramenta de recolha de dados e o sítio Web alvo, ocultando o seu verdadeiro endereço IP. Por endereços IP rotativosPara além disso, estes proxies ajudam a evitar serem detectados ou bloqueados por sítios Web que dispõem de mecanismos anti-raspagem.
- Rotação de IP: Muda automaticamente de endereço IP para evitar a deteção.
- Geo-Targeting: Permite a seleção de IPs de países ou regiões específicos.
- Anonimato elevado: Mantém a sua identidade oculta durante o scraping.
- Velocidade e fiabilidade: Assegura uma recolha de dados sem interrupções.
Porque é que o Proxy Scraper é importante?
- Os sítios Web bloqueiam frequentemente pedidos repetidos do mesmo IP. Os proxies distribuem os pedidos por vários IPs, reduzindo o risco de deteção.
- Os proxies proxy scraper ajudam a lidar com os limites de taxa, distribuindo o tráfego por vários IPs.
- Utilize proxies para visualizar conteúdos específicos da região, ocultando a sua localização.
- Evite CAPTCHAs e bloqueios, assegurando uma recolha de dados sem problemas.
Tipos de Proxies para Scraping
-
Procurações residenciais:
Atribuído pelos ISPs a dispositivos reais, altamente anónimo e o melhor para sítios Web restritos.
-
Proxies de centros de dados:
Mais rápido e mais barato, adequado para sítios menos seguros.
-
Proxies rotativos:
Altere os IPs automaticamente para scraping em grande escala.
-
Proxies estáticos:
Mantenha o mesmo endereço IP para garantir a consistência da sessão.
Como escolher o melhor raspador de proxy
Siga estas dicas para selecionar os proxies adequados às suas necessidades:
1. Considerar o sítio Web alvo
- Utilização procurações residenciais para sítios Web de alta segurança.
- Proxies de centros de dados funcionam bem para sítios menos seguros.
2. Procurar opções de rotação
A rotação de proxies reduz o risco de deteção e Proibições de IP.
3. Verificar a velocidade e o tempo de atividade
Certifique-se de que o raspador proxy oferece alta velocidade e tempo de atividade fiável para evitar interrupções durante a raspagem.
4. Capacidades de segmentação geográfica
Se precisar de dados de regiões específicas, escolha proxies que permitam a segmentação geográfica. (OkeyProxy oferece mais de 150 milhões de IPs de mais de 200 países e regiões, suportando a segmentação por cidade e ISP direcionamento).
Provedores de proxy recomendados para raspagem
Para uma recolha de dados da Web eficiente e fiável, é essencial utilizar um fornecedor de proxy fiável. OkeyProxy é uma óptima escolha, oferecendo:
- Rotação de mandatários residenciais: Perfeito para contornar proibições de IP e aceder a conteúdos específicos da região.
- Proxies de centro de dados de alta velocidade: Ideal para tarefas de raspagem rápidas e em grande escala.
- Cobertura global: Proxies de locais em todo o mundo para scraping geo-direcionado.

Passos para utilizar um raspador de proxy
A utilização de proxies é essencial para a recolha de dados da Web para manter o anonimato, evitar proibições de IP e contornar restrições. Abaixo estão as etapas detalhadas para usar efetivamente um proxy para raspagem:
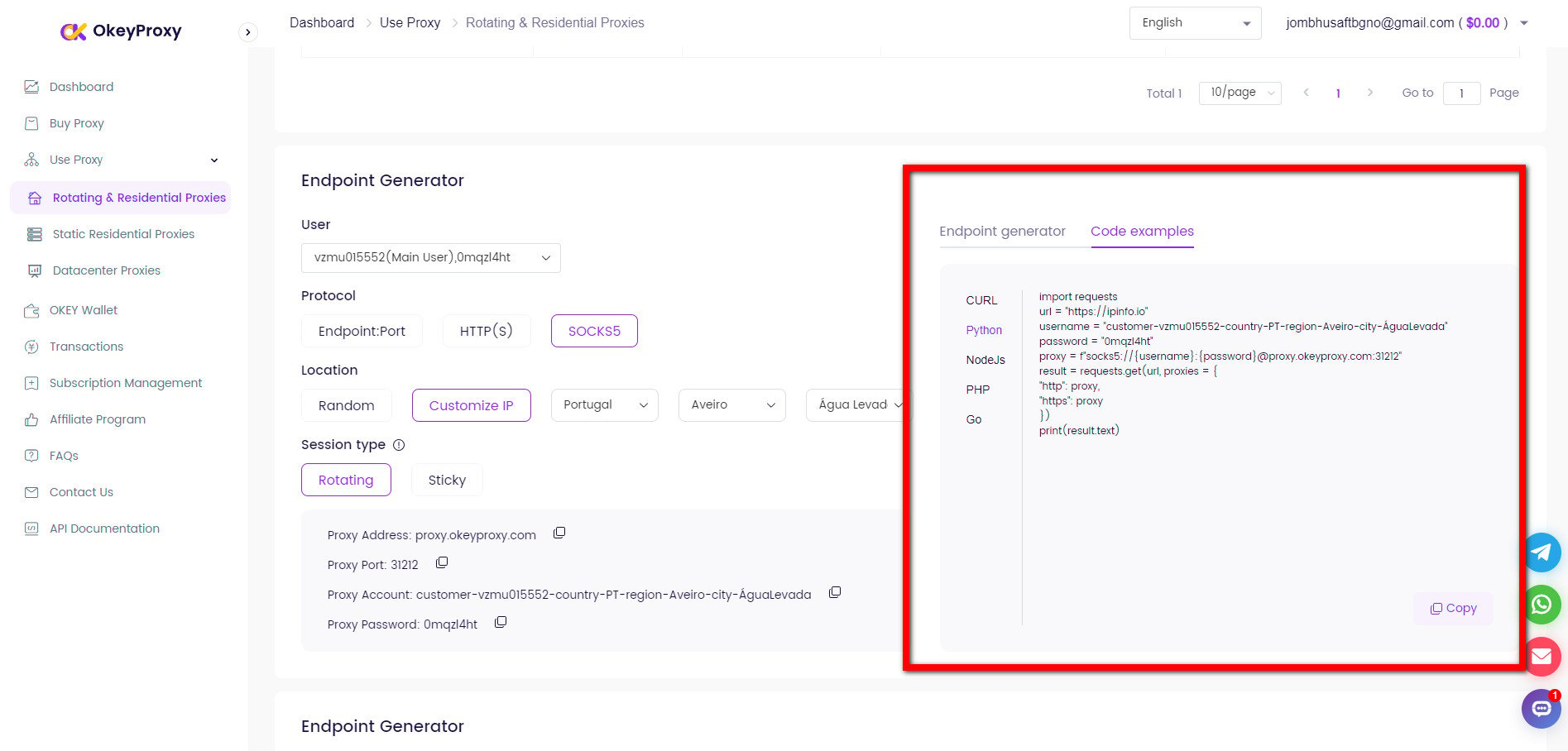
Pré. Obter detalhes do proxy
Diferentes proxies são adequados para várias necessidades de raspagem: Utilize um fornecedor fiável, OkeyProxyO sistema de gestão de tráfego é um sistema de gestão de tráfego que permite obter o endereço IP, a porta e outras informações do painel de controlo.


Serviço de proxy Socks5/Http(s) de alto nível
- Planos escaláveis: Proxies residenciais estáticos/rotativos
- Integração perfeita: Win/iOS/Android/Linux
- Alta segurança: Ideal para navegadores antidetectores, emuladores, scrapers, etc.
- Desempenho fiável: Transferência rápida e baixa latência
Nota: Evite proxies gratuitos para raspagem devido a potenciais riscos de segurança e instabilidade.
1. Scraping com base no navegador
Para ferramentas como o Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Opções()
chrome_options.add_argument('--proxy-server=http://your-proxy-server:port')
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://example.com')2. Ferramentas de linha de comando
Para ferramentas como cURL:
curl -x http://proxy-server:port http://example.com3. Bibliotecas (por exemplo, os pedidos de Python)
Definir o proxy no ficheiro pedidos biblioteca de Python:
pedidos de importação
proxies = {
"http": "http://your-proxy-server:port",
"https": "http://your-proxy-server:port",
}
response = requests.get('http://example.com', proxies=proxies)
print(response.text)4. Autenticação
Se o proxy exigir autenticação, forneça as credenciais:
proxies = {
"http": "http://username:password@proxy-server:port",
"https": "http://username:password@proxy-server:port",
}5. Limites de rotação/ritmo do manípulo
Para raspagem em grande escala:
- Utilização proxies rotativos para alterar IPs após cada pedido.
- Incorporar atrasos entre pedidos para imitar o comportamento humano.
Exemplo com pedidos e tempo por atraso:
tempo de importação
for url in url_list:
response = requests.get(url, proxies=proxies)
print(response.status_code)
time.sleep(2) # Atraso entre pedidosConclusão
Os scrapers proxy são essenciais para o sucesso da recolha de dados da Web, uma vez que ajudam a contornar bloqueios, a evitar a deteção e a garantir o acesso ininterrupto aos dados. Quer esteja a fazer scraping para fins de investigação, SEO ou de conhecimento do negócio, investir nos proxies certos irá poupar-lhe tempo e esforço, aumentando a sua eficiência.
Procura um raspador proxy fiável para apoiar as suas necessidades de raspagem? Considere a opção de OkeyProxyque oferece proxies seguros e de alta velocidade, perfeitos para tarefas de raspagem da Web.





