Nell'era digitale, i dati sono spesso definiti il nuovo oro. Le aziende, i ricercatori e i singoli individui si affidano ai dati per prendere decisioni informate, ottenere approfondimenti e rimanere competitivi. Il web scraping, il processo di estrazione dei dati dai siti web, è diventato uno strumento indispensabile per la ricerca di informazioni. Tuttavia, la ricerca sul Web non è priva di sfide, la più importante delle quali è la necessità di un agente. In questa guida completa, analizzeremo come sfruttare i proxy di scraping per migliorare i vostri sforzi di Data Scraping e darvi un vantaggio competitivotage.
Conoscere il Proxy Scraping
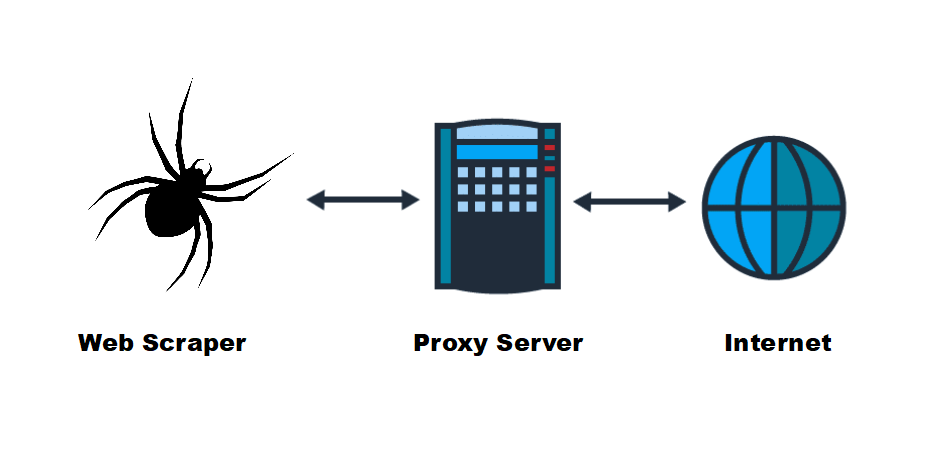
Prima di immergerci nell'uso dei proxy per lo scraping del Web, chiariamo innanzitutto cos'è e cosa fa un proxy. Un proxy funge da intermediario tra il vostro computer e il server Web a cui state cercando di accedere. Quando si utilizza un proxy per richiedere dati da un sito web, il server proxy effettua la richiesta per conto dell'utente, mascherando il suo indirizzo IP. Questo è fondamentale per le ricerche sul Web, in quanto consente di rimanere anonimi ed evitare di essere scoperti.
Perché utilizzare un proxy per lo scraping del web
A. Superare il blocco e le restrizioni IP
Molti siti web adottano misure anti-scraping per impedire la raccolta automatica dei dati. Possono bloccare gli indirizzi IP che effettuano un numero eccessivo di richieste in un breve periodo di tempo o limitare l'accesso agli utenti di regioni specifiche. Utilizzando un server proxy, si ruota attraverso un pool di indirizzi IP, rendendo difficile per i siti web rilevare e bloccare la vostra attività di ricerca.
B. Garantire l'anonimato e la privacy
Lo scraping di più pagine web o siti web senza un proxy può comportare il divieto di accesso al vostro indirizzo IP. Questo non solo interrompe la raccolta dei dati, ma compromette anche la vostra privacy. I proxy forniscono un ulteriore anonimato, assicurando che il vostro indirizzo IP reale sia nascosto durante lo scraping di dati dal web.
Tipo di proxy di scraping
Esistono diversi tipi di server proxy tra cui scegliere, ognuno con i propri vantaggi e utilizzi:
A. Delega residenziale
Un proxy residenziale è un indirizzo IP assegnato a un'area residenziale reale. Poiché hanno l'aspetto di connessioni utente legittime, sono molto affidabili per i siti web. I proxy residenziali sono ideali quando è necessario accedere ai dati di un sito web con misure di sicurezza rigorose.
B. Proxy del centro dati
Un proxy per data center è un indirizzo IP ospitato in un data center. I proxy dei centri dati sono più veloci ed economici dei proxy residenziali, ma potrebbero non essere altrettanto affidabili per i siti web. Data Center Agent è adatto per attività che richiedono velocità ed efficienza.
C.server proxy SOCKS
I server proxy SOCKS sono versatili e in grado di gestire tutti i tipi di traffico Internet, il che li rende una scelta popolare per le ricerche sul Web. Combinano vantaggi in termini di sicurezza e prestazioni, rendendoli una scelta completa per la raccolta dei dati.
D. Proxy rotante
I proxy a rotazione cambiano costantemente gli indirizzi IP, rendendo difficile per i siti web identificare e bloccare le attività di ricerca. Sono una scelta popolare per le operazioni di ricerca su larga scala.
Scegliere il giusto fornitore di proxy di scraping
La scelta del giusto provider di proxy è fondamentale per il successo dei vostri sforzi di ricerca sul web. Quando scegliete un provider, considerate fattori come l'affidabilità, la velocità, la copertura della posizione e il prezzo. Alcuni fornitori di proxy comunemente utilizzati sono Luminati, Oxylabs e Smartproxy.
Impostare e configurare un proxy di scraping
La configurazione di un proxy per lo scraping del web richiede la regolazione delle impostazioni dello strumento di scraping in modo che le richieste vengano instradate attraverso il server proxy. Inoltre, potrebbe essere necessario gestire l'autenticazione e implementare un sistema di rotazione proxy strategia per evitare di essere scoperti.
Le migliori pratiche per l'utilizzo di Scraping Proxy
Il Web Scraping non è una panacea e l'uso efficace di un server proxy richiede il rispetto delle migliori pratiche. Considerate l'utilizzo di limitazione e strozzatura della velocità, monitoraggio e registrazione e una solida gestione degli errori per garantire operazioni di ricerca senza intoppi.
Risoluzione dei problemi comuni del proxy
Nonostante i vostri sforzi, potreste incontrare problemi come il blocco degli IP e i CAPTCHA durante lo scraping del web. Imparare a risolvere questi problemi comuni legati agli agenti è fondamentale per mantenere un processo di raccolta dei dati senza interruzioni.
Studio di caso
Esempi reali di scraping web di successo con l'uso di proxy possono fornire preziose indicazioni su come applicare i proxy a varie situazioni. Questi casi di studio illustrano i vantaggi pratici dell'incorporazione degli agenti nel flusso di lavoro per la raccolta dei dati.
Conclusione
In sintesi, la ricerca sul Web è un potente strumento di raccolta dati e gli agenti sono la chiave per sbloccare tutto il suo potenziale. Utilizzando un proxy, è possibile superare il blocco degli IP, garantire l'anonimato e raccogliere i dati in modo più efficiente. Con il giusto fornitore di agenzie e le migliori pratiche, potete migliorare le vostre attività di raccolta dati e ottenere un vantaggio competitivo nel mondo odierno basato sui dati.
