Im digitalen Zeitalter werden Daten oft als das neue Gold bezeichnet. Unternehmen, Forscher und Privatpersonen sind auf Daten angewiesen, um fundierte Entscheidungen zu treffen, Erkenntnisse zu gewinnen und wettbewerbsfähig zu bleiben. Web Scraping, das Extrahieren von Daten aus Websites, ist zu einem unverzichtbaren Werkzeug bei der Informationssuche geworden. Die Websuche ist jedoch nicht ohne Herausforderungen, von denen die wichtigste die Notwendigkeit eines Agenten ist. In diesem umfassenden Leitfaden erfahren Sie, wie Sie Scraping-Proxys einsetzen können, um Ihre Data-Scraping-Bemühungen zu verbessern und sich einen Wettbewerbsvorteil zu verschaffentage.
Erfahren Sie mehr über Proxy Scraping
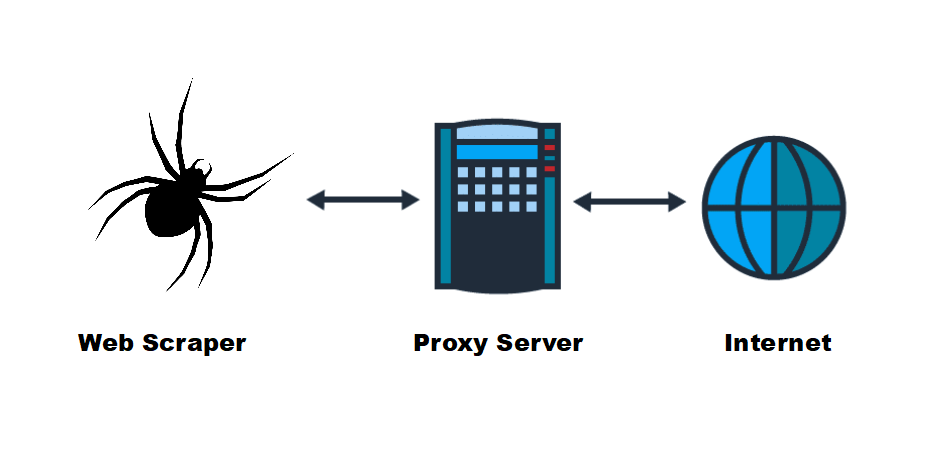
Bevor wir uns mit der Verwendung von Proxys für Web-Scraping beschäftigen, sollten wir zunächst klären, was ein Proxy ist und was er tut. Ein Proxy fungiert als Vermittler zwischen Ihrem Computer und dem Webserver, auf den Sie zugreifen möchten. Wenn Sie einen Proxy verwenden, um Daten von einer Website anzufordern, stellt der Proxy-Server die Anfrage in Ihrem Namen und maskiert dabei Ihre IP-Adresse. Dies ist für die Websuche von entscheidender Bedeutung, da Sie auf diese Weise anonym bleiben und nicht entdeckt werden können.
Warum einen Proxy für Web Scraping verwenden?
A. Überwindung von IP-Sperren und Einschränkungen
Viele Websites setzen Anti-Scraping-Maßnahmen ein, um eine automatische Datenerfassung zu verhindern. Sie können IP-Adressen blockieren, die in einem kurzen Zeitraum zu viele Anfragen stellen, oder den Zugang auf Nutzer in bestimmten Regionen beschränken. Wenn Sie einen Proxy-Server verwenden, wechseln Sie durch einen Pool von IP-Adressen, was es für Websites schwierig macht, Ihre Suchaktivitäten zu erkennen und zu blockieren.
B. Gewährleistung von Anonymität und Datenschutz
Das Scraping mehrerer Webseiten oder Websites ohne einen Proxy kann dazu führen, dass Ihre IP-Adresse gesperrt wird. Dies unterbricht nicht nur Ihre Datensammlung, sondern gefährdet auch Ihre Privatsphäre. Proxys bieten zusätzliche Anonymität und sorgen dafür, dass Ihre echte IP-Adresse beim Scraping von Daten aus dem Internet verborgen bleibt.
Art der Scraping-Proxys
Es gibt verschiedene Arten von Proxy-Servern, jeder mit seinen eigenen Vorteilen und Einsatzmöglichkeiten:
A. Wohnsitzvollmacht
Ein Residential Proxy ist eine IP-Adresse, die einem echten Wohngebiet zugewiesen ist. Da sie wie legitime Benutzerverbindungen aussehen, genießen sie bei Websites großes Vertrauen. Residente Proxys sind ideal, wenn Sie auf Daten von einer Website mit strengen Sicherheitsmaßnahmen zugreifen müssen.
B. Rechenzentrums-Proxy
Ein Rechenzentrums-Proxy ist eine IP-Adresse, die in einem Rechenzentrum gehostet wird. Rechenzentrums-Proxys sind schneller und kostengünstiger als Proxys für Privatanwender, werden aber von Websites möglicherweise nicht als vertrauenswürdig eingestuft. Data Center Agent eignet sich für Aufgaben, die Geschwindigkeit und Effizienz erfordern.
C.SOCKS-Proxy-Server
SOCKS-Proxyserver sind vielseitig und können alle Arten von Internetverkehr verarbeiten, was sie zu einer beliebten Wahl für die Websuche macht. Sie vereinen Sicherheits- und Leistungsvorteile, was sie zu einer umfassenden Wahl für die Datenerfassung macht.
D. Drehende Vollmacht
Rotierende Proxys ändern ständig ihre IP-Adressen, was es für Websites schwierig macht, Suchaktivitäten zu erkennen und zu blockieren. Sie sind eine beliebte Wahl für groß angelegte Suchvorgänge.
Wählen Sie den richtigen Anbieter von Scraping-Proxys
Die Wahl des richtigen Proxy-Anbieters ist entscheidend für den Erfolg Ihrer Web-Suche. Berücksichtigen Sie bei der Auswahl eines Anbieters Faktoren wie Zuverlässigkeit, Geschwindigkeit, Standortabdeckung und Preis. Einige häufig verwendete Proxy-Anbieter sind Luminati, Oxylabs und Smartproxy.
Einrichten und Konfigurieren eines Scraping Proxies
Um einen Proxy für Web Scraping zu konfigurieren, müssen die Einstellungen des Scraping-Tools so angepasst werden, dass die Anfragen über den Proxy-Server geleitet werden. Außerdem müssen Sie möglicherweise die Authentifizierung handhaben und eine Proxy-Rotation Strategie, um nicht entdeckt zu werden.
Bewährte Praktiken für die Verwendung des Scraping-Proxys
Web Scraping ist kein Allheilmittel, und die effektive Nutzung eines Proxyservers erfordert die Einhaltung bewährter Verfahren. Erwägen Sie die Verwendung von Ratenbegrenzung und Drosselung, Überwachung und Protokollierung sowie eine robuste Fehlerbehandlung, um reibungslose Suchvorgänge zu gewährleisten.
Fehlerbehebung bei allgemeinen Proxy-Problemen
Trotz Ihrer besten Bemühungen können Sie beim Scraping im Web auf Probleme wie IP-Sperren und CAPTCHAs stoßen. Die Behebung dieser häufigen Probleme im Zusammenhang mit Agenten ist entscheidend für die Aufrechterhaltung eines reibungslosen Datenerfassungsprozesses.
Fallstudie
Beispiele aus dem wirklichen Leben für erfolgreiches Web Scraping mit Proxys können Ihnen wertvolle Einblicke in die Anwendung von Proxys in verschiedenen Situationen geben. Diese Fallstudien veranschaulichen die praktischen Vorteile der Einbindung von Agenten in Ihren Datenerfassungs-Workflow.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass die Websuche ein leistungsfähiges Instrument zur Datenerfassung ist, und dass Agenten der Schlüssel dazu sind, ihr volles Potenzial auszuschöpfen. Durch die Verwendung eines Proxys können Sie IP-Sperren umgehen, Anonymität gewährleisten und Daten effizienter sammeln. Mit dem richtigen Anbieter und bewährten Verfahren können Sie Ihre Datenerfassung verbessern und sich in der heutigen datengesteuerten Welt einen Wettbewerbsvorteil verschaffentage.
")





