
Récupération de comptes d'utilisateurs sur Instagram et TikTok implique la collecte de données sur ces plateformes. Il est important de noter que le scraping de ces plateformes peut constituer une violation de leurs conditions d'utilisation et entraîner des interdictions de compte ou des conséquences juridiques. C'est pourquoi il convient d'utiliser Proxy La rotation de l'adresse IP est une astuce nécessaire pour le web scraping. Dans cette optique, voici un guide étape par étape pour extraire des données utilisateur de l'interface web d'Instagram/TikTok !
Comment récupérer des comptes d'utilisateurs sur IG et TikTok avec Python
Voyons comment récupérer les données de profil des utilisateurs sur Instagram et TikTok, notamment le nom d'utilisateur, le nom complet, la description et l'image de profil.

Étape 1 : Configuration de l'environnement
- Installer Python et Pip : Assurez-vous que Python est installé sur votre machine. Vous pouvez le télécharger à partir de python.org. Pip, l'installateur de paquets pour Python, est généralement fourni avec les installations Python.
- Installer les bibliothèques requises :
pip install requests beautifulsoup4 pandas selenium - Télécharger Webdriver : Pour Selenium, vous devez télécharger le WebDriver approprié pour votre navigateur. Pour Chrome, vous pouvez obtenir ChromeDriver à partir de ici.
Étape 2 : Créer un scraper pour Instagram
A. Récupération de données publiques
Configuration de base :
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Fonction pour obtenir le contenu HTML
def get_html(url) :
response = requests.get(url)
return response.textExtraction d'informations sur les utilisateurs :
def scrape_instagram_user(username) :
url = f'https://www.instagram.com/{nomd'utilisateur}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extraction des données pertinentes
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('meta', {'property' : 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property' : 'og:description'})['content']
user_data['profile_image'] = soup.find('meta', {'property' : 'og:image'})['content']
return user_data
# Exemple d'utilisation
user = scrape_instagram_user('instagram')
print(utilisateur)B. Gestion du contenu dynamique avec Selenium
Configurer Selenium :
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
# Configuration de WebDriver
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Fonction pour obtenir du contenu dynamique
def get_dynamic_content(url) :
driver.get(url)
time.sleep(3) # Attendre le chargement de la page
return driver.page_source
# Exemple d'utilisation
html = get_dynamic_content('https://www.instagram.com/instagram/')Étape 3 : Créer un scraper pour TikTok
A. Récupération de données publiques
Configuration de base :
def scrape_tiktok_user(nom d'utilisateur) :
url = f'https://www.tiktok.com/@{nomd'utilisateur}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extraction des données pertinentes
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('h1', {'data-e2e' : 'user-title'}).text if soup.find('h1', {'data-e2e' : 'user-title'}) else None
user_data['description'] = soup.find('h2', {'data-e2e' : 'user-subtitle'}).text if soup.find('h2', {'data-e2e' : 'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class' : 'avatar'})['src'] if soup.find('img', {'class' : 'avatar'}) else None
return user_data
# Exemple d'utilisation
user = scrape_tiktok_user('tiktok')
print(user)B. Gestion du contenu dynamique avec Selenium
Configurer Selenium :
# Réutiliser la configuration Selenium de la section Instagram
# Exemple d'utilisation pour TikTok
html = get_dynamic_content('https://www.tiktok.com/@tiktok')Étape 4 : Enregistrer les données au format CSV
Sauvegarde des données :
def save_to_csv(data, filename='output.csv') :
df = pd.DataFrame(data)
df.to_csv(nom_de_fichier, index=False)
# Exemple d'utilisation
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')]
save_to_csv(data)Étape 5 : Utilisation de serveurs mandataires et gestion de la limitation du débit
Utilisation de proxies pour récupérer les données d'Instagram et de TikTok, comme OkeyProxy, a proxy pour le scraping webest essentiel pour contourner les limites de taux et les restrictions d'accès à l'Internet. Interdictions d'IP Les proxys imposés par la plateforme sont conçus pour empêcher l'extraction excessive de données et maintenir l'intégrité de leur service. Les proxys vous permettent de répartir vos demandes de scraping sur plusieurs adresses IP, ce qui réduit la probabilité d'être signalé comme un utilisateur suspect et garantit un accès continu aux données dont vous avez besoin. Cela est particulièrement important sur des plateformes comme TikTok, où des volumes élevés de requêtes peuvent déclencher des défenses automatisées qui bloquent ou limitent l'accès. En utilisant des proxys, vous pouvez maintenir une opération de scraping stable et efficace, en collectant des données sans subir d'interruptions significatives.
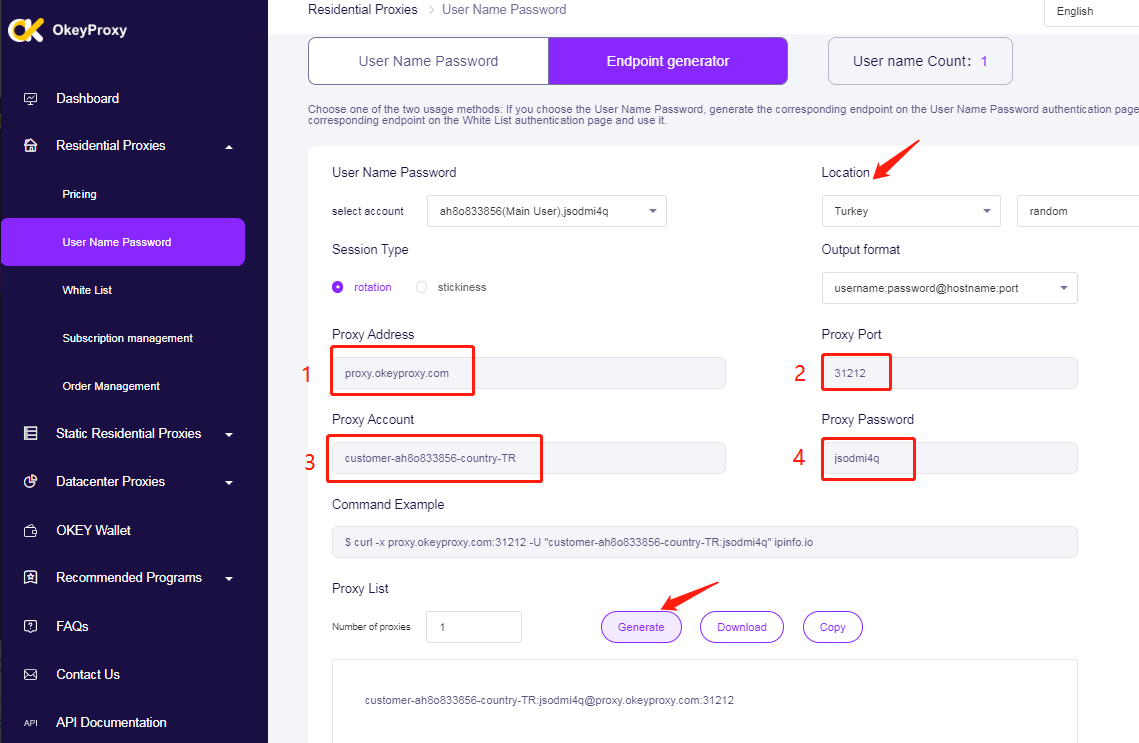
Configurer les Proxies :
proxies = {
'http' : 'http://your_proxy_here',
'https' : 'https://your_proxy_here',
}
# Exemple d'utilisation avec des requêtes
response = requests.get(url, proxies=proxies)Gestion de la limitation du débit :
temps d'importation
# Fonction pour ajouter un délai
def delayed_request(url, delay=2) :
time.sleep(delay)
return get_html(url)Exemple d'étude de cas pour récupérer des données sur Instagram et TikTok
Scénario
Vous êtes chargé de récupérer les données de profil de quelques utilisateurs d'Instagram et de TikTok afin d'analyser leur présence sur les médias sociaux dans le cadre d'une campagne de marketing.
Étapes
- Environnement d'installation : Assurez-vous que toutes les bibliothèques requises sont installées et que le WebDriver est configuré.
- Récupérer les données des utilisateurs d'Instagram:
instagram_usernames = ['instagram', 'cristiano', 'natgeo'] instagram_data = [] pour nom d'utilisateur dans instagram_usernames : user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - Récupérer les données des utilisateurs de TikTok:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock'] tiktok_data = [] pour nom d'utilisateur dans tiktok_usernames : user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - Gérer le contenu dynamique avec Selenium : Utilisez la configuration Selenium pour récupérer la source de la page et analyser les données pour les profils avec un contenu dynamique.
Autre méthode : Récupérer les comptes d'utilisateurs de Instagram/Tiktok avec l'API
Utiliser l'API Instagram
Instagram propose une API qui permet d'accéder aux données publiques. Cependant, cette API est limitée et nécessite une approbation, ce qui la rend moins flexible pour le scraping à grande échelle.
- Créez un compte de développeur sur Facebook for Developers.
- Créer une application d'affichage de base Instagram.
- Utilisez les points de terminaison de l'API pour accéder aux données de l'utilisateur, y compris les profils d'utilisateur et les médias.

Utiliser l'API TikTok
TikTok propose une API publique permettant d'accéder à certaines données des utilisateurs, mais comme Instagram, elle comporte des limites et nécessite une approbation.
- Demandez l'accès à l'API TikTok via le portail des développeurs.
- Utiliser les points de terminaison de l'API pour collecter les profils et le contenu des utilisateurs.

Considérations sur la récupération des comptes d'utilisateurs sur Instagram/Tiktok
- Assurez-vous que vous avez le droit d'extraire les données et que vous respectez les conditions d'utilisation de la plateforme.
- Mise en œuvre de délais et d'une utilisation appropriés mandataires pour éviter d'être bloqué.
- Traitez les données récupérées de manière responsable et respectez la vie privée des utilisateurs.
Résumé
C'est tout. En suivant ces étapes pour extraire des données via Python avec Proxy ou l'API originale de la plateforme, vous pouvez gratter des comptes d'utilisateurs sur Instagram et TikTok de manière efficace tout en restant conforme aux directives légales et éthiques.
